
-
2021.03.24 - [✎ 21.上/Data] - [티스토리 게시글 추천 시스템 만들기] #1 계획
한글만 분석하기 위해 한글 형태소 분석기를 사용했다. 나는 이 중에 정규화까지 가능하다는 OKT를 사용했다.
tag Package — KoNLPy 0.5.2 documentation
Parameters: jvmpath – The path of the JVM passed to init_jvm(). userdic – The path to the user dictionary. This enables the user to enter custom tokens or phrases, that are mandatorily assigned to tagged as a particular POS. Each line of the dictionary
konlpy.org
사실.. HDFS에 저장할 필요도 없이 바로 HIVE로 쏠까 했는데 다 한번씩 만져보고싶어서 HDFS에 중간에 한번 저장하는 과정을 거쳤다.
from typing import List, Optional from bs4 import BeautifulSoup import requests import logging import re from konlpy.tag import Okt from pyspark.sql import SparkSession from tqdm import tqdm logger = logging.getLogger() def analysis_nlp(texts: List) -> List: okt = Okt() article_pos_list = [] for text in texts: article_pos = okt.pos(text) if article_pos: for pos in article_pos: article_pos_list.append({"morpheme": [pos[1]], "text": [pos[0]]}) return article_pos_list def get_content_main(post_num: int) -> List: contents: List = [""] * 500 for num in tqdm(range(1, post_num)): result = get_content(num) if result: contents[num]: Optional[List] = result else: logger.warning("존재하지 않는 게시글입니다.") total_pos = [] for content in contents: if content: nlp_set: list = analysis_nlp(content) total_pos.extend(nlp_set) return total_pos def get_content(post_num: int) -> Optional[List]: url: str = "https://weejw.tistory.com/%d" % post_num content = requests.get(url).content logger.info("URL:%s" % url) soup = BeautifulSoup(content, 'html.parser') exists_post = soup.select_one('div.absent_post') if exists_post is not None: return None contents = soup.select_one('div.tt_article_useless_p_margin') if contents is None: return None results: str = str(contents.findAll('p')) results: List = re.sub('<.+?>', '', results).replace("[", "").replace("]", "").split(",") results: List = [result for result in results if (result not in ['', ' '])] return results if results else None def get_spark_session(): app_name = "Python Example - PySpark Parsing Dictionary as DataFrame" master = "local" spark = SparkSession.builder \ .appName(app_name) \ .master(master) \ .getOrCreate() return spark def log_init(): logger.setLevel(logging.INFO) formatter = logging.Formatter('%(asctime)s [%(levelname)s]: %(message)s') stream_handler = logging.StreamHandler() stream_handler.setFormatter(formatter) logger.addHandler(stream_handler) def main(): log_init() spark = get_spark_session() #total_pos = get_content_main(post_num=500) #spark_df = spark.createDataFrame(total_pos) file_path = "hdfs://localhost:9000/user/jiwonwee/crawler_data/crawler_data.parquet" # HDFS에 파일 저장 spark_df.write.parquet(file_path) if __name__ == '__main__': main()HDFS에 저장된 파일을 다시 불러와서 출력하면 다음과 같다. 굿 ^_^
spark_df = spark.read.parquet(file_path) spark_df.show()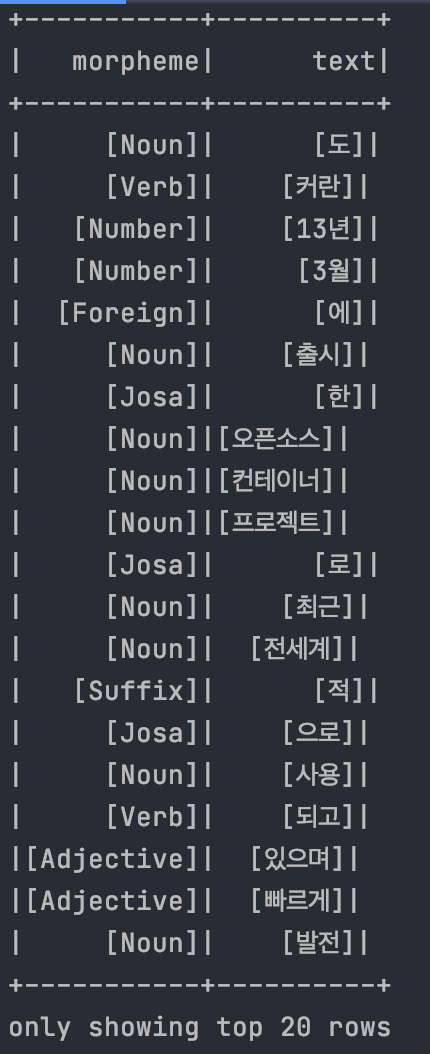
REFERENCES
[Python] 한국어 형태소 분석기 체험 및 비교(Okt, Mecab, Komoran, Kkma)
[Python] 한국어 형태소 분석기 체험 및 비교(Okt, Mecab, Komoran, Kkma) Published Jun 07, 2020 한국어는 영어처럼 띄어쓰기만으로 단어를 분리하면 제대로 되질 않습니다. 한국어는 어미와 조사 등이
soohee410.github.io
macOS에서 Hadoop 설치하기
rap0d.github.io
hadoop - HBase 및 Parquet 파일에 데이터 저장 - IT 툴 넷
hadoop - HBase 및 Parquet 파일에 데이터 저장 출처 hadoop hbase parquet phoenix 저는 빅 데이터를 처음 사용하고 데이터를 유지하고 검색하는 다양한 방법을 이해하려고합니다. Parquet과 HBase는 열 지향 저장
pythonq.com
apache-spark 시작하기(Macbook), spark 설치, pyspark
스파크 사용 이유는? 먼저 데이터가 엄청난 양으로 증가되며, 이를 처리하기 위해 분산 프레임워크인 Hadoop과 최근에 Spark가 많이 쓰이고 있다. Hadoop은 데이터를 수집하는 목적으로 많이 사용된
parkaparka.tistory.com
'2021년 > Data' 카테고리의 다른 글
[티스토리 게시글 추천 시스템 만들기] #4 worldCloud 만들기 (0) 2021.03.26 [티스토리 게시글 추천 시스템 만들기] #3 클롤링 데이터 TF-IDF 계산하기 (0) 2021.03.25 [티스토리 게시글 추천 시스템 만들기] #1 계획 (0) 2021.03.24 koalas (0) 2021.03.23 [DB 공부] PostgreSQL Query (0) 2021.03.22
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
