
-

한달만에 글을 작성한다.. 요근래 좀 바빴다.. 티스토리가 많이 바뀌었다. 이모티콘을 넣을 수 있네.. 내가 구매한 이모티콘도 여기서 쓸 수 있으면 좋겠다.(나는 이모티콘 구매가 100개가 넘는다 ㅇ.< 소소한 취미다)
아무튼, 오늘 작성할 글은 GCP에 대한 글이다. GCP Bigquery를 이용해서 ML 학습까지 진행하고 DataStudio이용까지 진행한다. 렛츠꼬!
1. GCP 무료 체험판 크레딧 받기.
계정을 새로만들면 무료 크레딧을 받을 수 있다. 나는 약 이미 어느정도 사용을 했다.

2. 새 프로젝트 생성
일단 기본적으로 프로젝트를 하나 생성해줘야한다. 그리고나서 Bigquery랑 Model deploy를 위해 Cloud Stroage 2개를 picked 해준다. 이게 은근히 생각보다 편하다... 나중에..,,

3. 공개 데이터 import
1) 공개 데이터 import
테이블을 만들어서 진행할 수도 있겠지만,, 귀찮다.
탐색기 옆에 데이터 추가가 있다. 여기서 공개 데이터세트를 탐색하고 'london_bicycles'를 입력해서 이 데이터 세트를 import 해주자.
그럼 public data가 탐색기에 추가된다. 우린 여기서 london bicycle만 이용할 것이다.

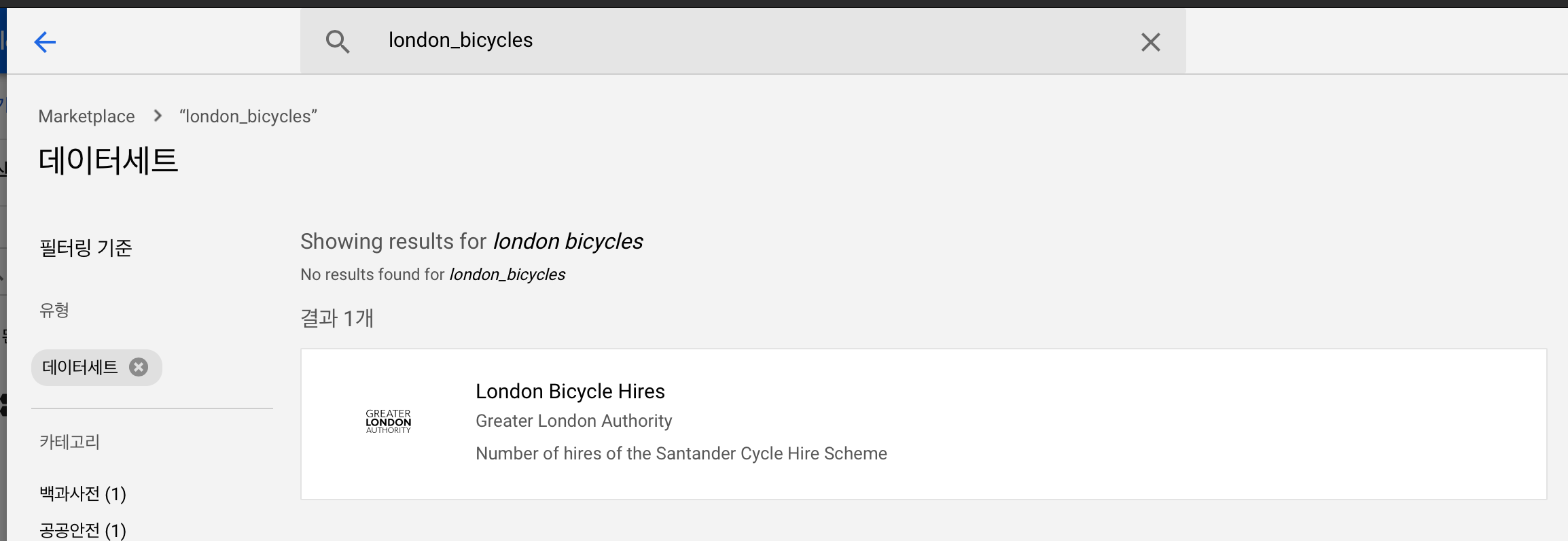

2) 필요한 데이터 세트만 겟또
공개 데이터를 그대로 이용하려고 하니 퍼미션에러가 떴다. 그냥 select은 퍼미션이 안뜨는데 왜 모델 크리에이트는..뜨는지
그래서 내 플젝으로 필요한 런던 자전거 데이터만 뜯어오기로 했다.

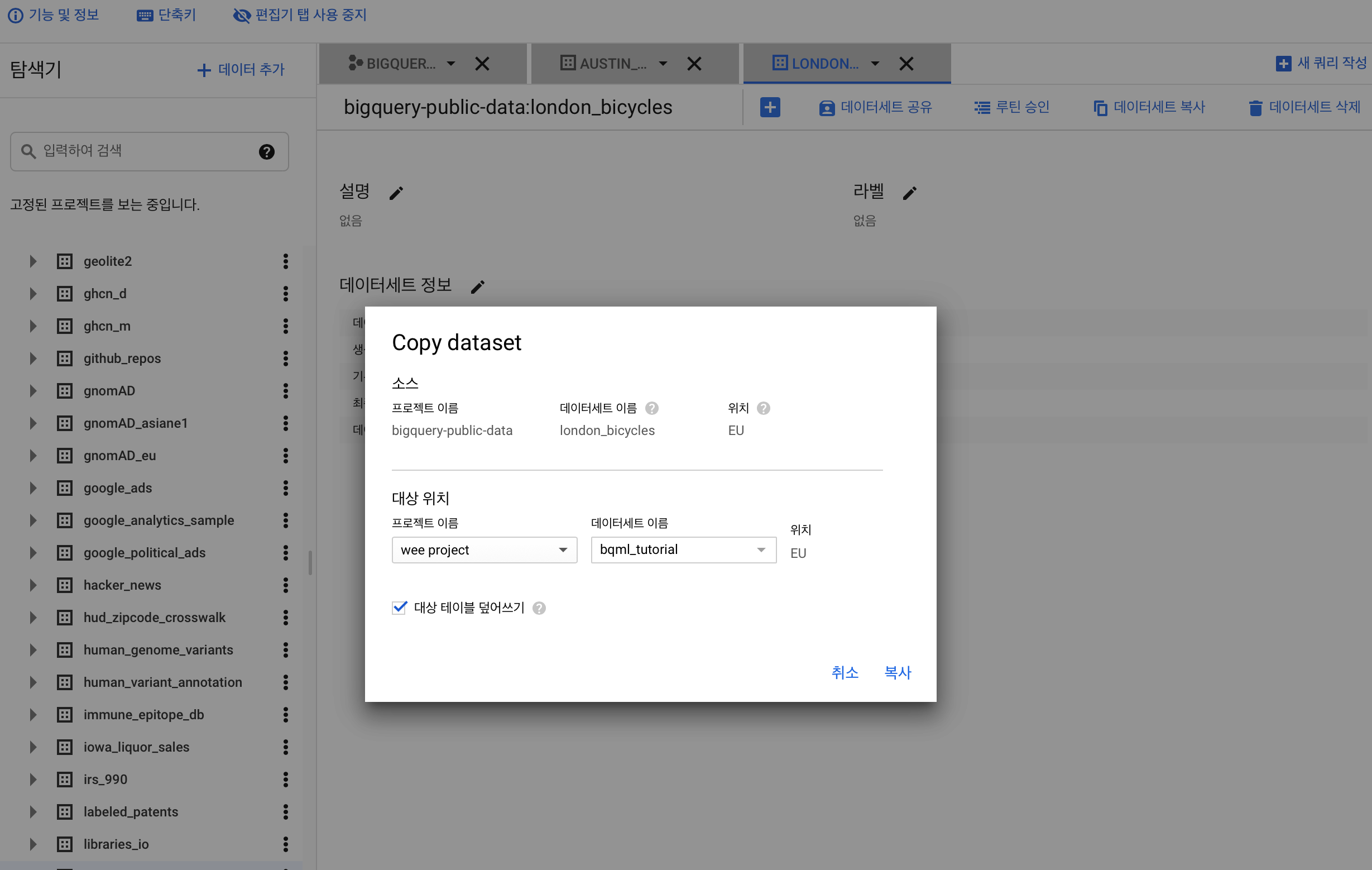

로 복제하면 다음과같은 오류가 뜬다. 그냥 제일 뒷쪽에 있는 주소로 가서 API 설정해주면된다.
데이터세트 복사 오류: BigQuery Data Transfer service has not been used in
그래도 안된다. vq가 대체 뭐란말인가 검색해도 안나온다. ㅡㅡ 
그래서 결국 그냥 테이블을 복제하는방법으로 진행해서 데이터를 뜯어왔다.
4. 서비스 계정 만들고 키 얻어오기
서비스계정 서비스로 가서 계정을 만들면 키를 만들 수 있다. 이를 json으로 다운받아서 잘 보관해둔다.
1) 서비스 계정 생성


2) 키 보관 및 client 생성
그리고나서 작업할 곳에 안전하게 보관한다.

그리고나서 파이썬 스크립트에 아래를 작성해서 자격을 얻어오기 위한 변수를 생성하고 bigquery를 이용할 때 사용할 클라이언트를 얻어온다.
credentials = service_account.Credentials.from_service_account_file( r'my_key.json' ) client = bigquery.Client(credentials=credentials)5. 필요한 라이브러리 설치
pip install --upgrade google-api-python-client pip install google-cloud-bigquery-storage pip install google-cloud-bigquery pip install pandas pip install pyarrow6. API 사용하기.
아래 페이지에서 쿼리를 따온다. 쿼리 해석은 그렇게 어렵지 않다.
k-평균 클러스터링 모델 만들기 | BigQuery ML | Google Cloud
소개 데이터에는 자연적인 데이터 그룹 또는 클러스터가 포함될 수 있습니다. 데이터 기반 의사 결정을 위해서는 이러한 그룹을 설명적으로 식별하는 것이 좋습니다. 예를 들어 소매업체라면
cloud.google.com
이를 이용해 간단한 스크립트를 하나 실행해보자. 아래 스크립트는 Sql로 얻어온 결과를 dataframe으로 출력하게 한다.
def check_data(): sql = f''' {{위 페이지에서 얻어온 쿼리문}} ''' return client.query(sql).to_dataframe() print(check_data())
전혀 문제없이 잘된다 :) 이때, 퍼미션 에러 안떴다 ㅠ_ㅠ 7. 모델 생성하기
같은 방식으로 위 페이지에서 모델 생성 쿼리를 복사해와서 진행하면된다.
1) feature_table 만들기
나는 predict를 한번에 모든 row에 대해서 하고싶어서 쿼리문을 조금 수정했다.
수정된 쿼리문은 아래와 같다. 그냥 모델 피쳐 테이블을 따로 만들어두었다.
create table `wee-project-313707.london_bicycles.model_faeture` AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `wee-project-313707.london_bicycles.cycle_hire` AS h JOIN `wee-project-313707.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday) select * except(isweekday) from stationstats2) 모델 생성하기
위에서 쿼리문을 다시 짯으니까,, 그냥 station_name만 빼주면된다. 학습에 사용되지 않도록
def create_model(): sql = f''' CREATE OR REPLACE MODEL `wee-project-313707.london_bicycles.london_station_clusters` OPTIONS(model_type='kmeans', kmeans_init_method = 'KMEANS++', num_clusters=3) AS SELECT * EXCEPT (station_name) FROM ( SELECT DISTINCT * FROM `wee-project-313707.london_bicycles.model_faeture` ) ''' res = client.query(sql) res.result() create_model()

역시나 문제없다 :) 8.Predict
아래 코드를 이용해서 Predict를 진행한다. (앗 오타 ㅜㅜ feature인데..) 그럼 정류장마다 centroid id 부여가 가능하다.
project_id = "wee-project-313707" data_set = "london_bicycles" cluster_result_table = "predict_res" model_name = "london_station_clusters" final_feature_data = "model_faeture" def predict(): sql = f''' CREATE OR REPLACE TABLE `{project_id}.{data_set}.{cluster_result_table}` AS SELECT * FROM ML.PREDICT(MODEL `{project_id}.{data_set}.{model_name}`, ( SELECT * FROM `{project_id}.{data_set}.{final_feature_data}`)) ''' res = client.query(sql) res.result() predict()
9. DataStudio
아래 쿼리문으로 나온 결과를(그냥 테이블 자체에서 진행해도된다. 그럼 row수가 더 많아지게쬬?) 아래와 같이 DataStudio를 이용해
간단한 시각화도 가능하다. ^_^ 굿


'2021년 > Data' 카테고리의 다른 글
[티스토리 게시글 추천 시스템 만들기] #5 Scrapy로 스크랩하기 (0) 2021.04.20 추천 시스템의 기본, 협업필터링(collaborative filtering) (0) 2021.04.20 Amazon Personalize는 어떻게 동작하는걸까? (2) 2021.04.09 [Spark] Data Analytics with Spark using Python - 기초 함수 (0) 2021.04.06 vmware fushion을 이용한 스파크 완전분산 모드(CentOS+MAC) (0) 2021.04.01
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
