
-
그동안 너무 바빠서 블로그에 글을 전혀 못썼다..
하루평균 12시간을 일하고 있,,, 오랜만에 짬이나서 핸드폰으로 간단하게 몇 자 적어보려한다. 그래서 글이 짧을 수 있음 >.<
스쿱이란?
스쿱은 Rdbms와 Haddop 사이에서 데이터 이관을 지원하는 툴이다. 현재 나도 Oracle data를 Kudu나 hive에 적재하는 데에 사용 중이다.
클라우데라에서 개발했으며 아파치 오픈 소스였으나 현재는 더 이상 릴리즈되지 않는 것 같다. 공식 홈피에 가면
This project has retired. For details please refer to its Attic page.
라고 적혀있다.
스쿱 아키텍쳐는 다음과 같다.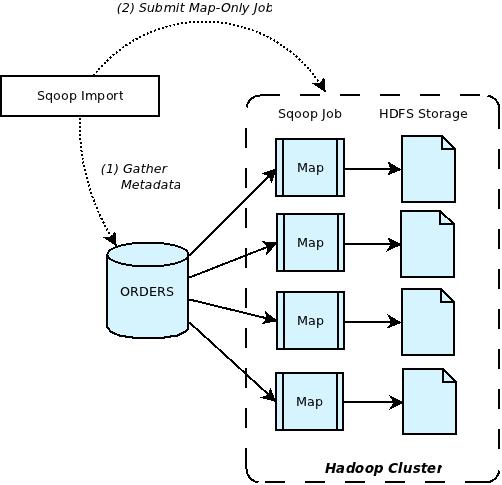
https://blogs.apache.org/sqoop/entry apache_sqoop_overview 끌어올 테이블의 메타데이터를 먼저 fetch하고 이를 기반으로 Java ORM을 생성하고 jar파일이 만들어진다. 이 작업을 통해서 rdbms와 HDFS의 data type이 자동으로 매핑된다.이 파일을 기반으로 map이 수행된다. 모든게 성공적이라면 이후에 Map 작업을 진행한다. 특이점은 Reduce가 없다는 점이다.
스쿱 사용법은 아래를 참고하면 좋다.Sqoop 사용
guide.ncloud-docs.com
성능을 올리는 법으로는 아래 옵션을 조정해주면 된다.
+batch
+split-by and boundary-query
+direct (mysql,postgresql)
+fetch-size
+num-mapper
자세한 내용은 아래 링크를 참고하자.SQOOP Performance tuning
Sqoop Overview Sqoop is a tool designed to transfer data between Hadoop and relational databases or mainframes. You can use Sqoop to import data from a relational database management system (RDBMS) such as MySQL or Oracle or a mainframe into the Hadoop Dis
community.cloudera.com
나는 split by랑 boundary query가 매우 햇갈렸었다.
split by는 데이터를 가져올 때 기준이 되는 컬럼으로 보통 파티션 키컬럼등을 사용한다.
boundary query는 스플릿을 생성하기 위하여 사용하는 경계 쿼리라고 공식문서에 적혀있다. 지정하지 않으면 키컬럼의 min max를 알아서 찾아서 하는데 좋은 방법이 아니므로 지정해주면 좋다.
나는 select 0,2 from dual 이렇게 넣어서 사용했었다.
sqoop에서 나는 가장 많이 사용하는 게 --query 옵션이었다. 테이블과 컬럼 옵션을 통해 테이블을 통째로 가져올 수도 있지만 freeform query를 통해서 여러가지 조건이나 aggregation등을 사용하여 데이터를 가져올 수 있다'2022년 > Developement' 카테고리의 다른 글
프로젝트를 마치며 #2. Kudu 와 Hive (0) 2022.12.27 프로젝트를 마치며 #1. 데이터 검증 (4) 2022.12.26 nifi+kakfa+hdfs 연결해보기 (0) 2022.08.10 Nifi 설치 및 실행, 예제 및 kafka, hdfs연결해보기 (0) 2022.08.09 Apache Nifi란? (0) 2022.08.08
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
