
-
http://weejw.tistory.com/35 무려 작년 7월초 spark streaming을 공부해보자 라는 게시글에
.... 드디어 스트리밍 공부를 한다! ٩(ˊᗜˋ*)و
Spark Streaming
스트리밍 데이터는 날씨나 log 데이터 처럼 계속해서 생성되어 쌓이는 데이터를 말한다.
SparkStreaming은 이 데이터를 배치 주기를 짧게 나누어서 실시간인 것처럼 처리 하는것이다.

출처 : spark 공식 사이트
연속 된 데이터 스트림을 Discretized Stream 또는 DStream이라고 하며 일련의 RDD로 표현된다. DStram은 입력 데이터로부터 생성하거나 다른 DStream으로부터 연산결과로 생성할 수 있다.
DStream
1) 연속된 데이터를 나타내기 위한 추상모델
2) 데이터를 읽어서 spark에서 사용할 데이터 모델 인스턴스를 생성
3) 여러가지 소스로부터 DStream을 생성할 수 있도록 별도의 메서드를 제공하여 지원

출처 : spark 공식 사이트
Streaming Context원래 spark에서는 RDD를 사용하기 위해 SparkContext를 사용하였다.http://weejw.tistory.com/180 이처럼 스트리밍 모듈을 사용하려면 StreamingContext 인스턴스를 생성해야한다.

스트리밍 컨텍스트는 특징이 있는데
1) 명시적인 시작, 대기 , 종료 메서드(종료시 sparkcontext도 같이 중지)
2) 스트리밍 컨텍스트가 시작되면 새로운 연산의 정의/추가 불가능
3) 종료 후 다시 시작 불가능
Streaming Context를 시작하고 나서는 아래의 순서로 수행을 한다.
1) 입력 DStreaming을 생성하여 입력 소스 정의
2) Transformation, 출력 연산을 Dstream에 적용하여 스트리밍 처리를 정의
3) start()로 소스로부터 데이터 읽고처리
4) awaitTermination()으로 처리가 중지될때까지 대기
5) stop으로 끝
예제를 따라해보자.(소켓)
공식 홈페이지 예제를 보면 코드로 직접 입력해서 할 수도 있지만... 코드 입력하기 귀찮으면 spark exmaple에 준비해두었단다! (´▽`)✿
1) spark 설치 폴더로 이동하여서 아래와 같이 예제를 실행하자 뒤에 ip는 소켓을 열어 데이터를 보낼 친구의 ip이다

2) 이제 다른 친구의 터미널에서 $nc -lk[엘케이]를 입력하여 소켓을 열고 메세지를 보내보자.

3) 그럼 아래와 같이 아까 예제를 실행한 터미널에서 전송 된 데이터를 시간 단위로 받는것을 알 수 있다.

4) 당연히 같은 단어를 한줄에 보내면 ( 예를들어 why not not not을 보내보자 ) 아래와 같이 카운팅 되어 출력한다.

- 연산
1) RDD가 제공하는 연산과 동일
2) window연산
일정 기간 동안 들어온 데이터를 한꺼번에 처리하기 위해 사용한다. 아래의 그림에서 볼 수 있듯이 원래 DStream에서 Windowed DStream을 생성하며 윈도우의 길이(windowLength)와 특정 시간(slideInterval)을 지정해주어야한다.
window(windowLength,slideInterval)

출처 : spark 공식 사이트
공식사이트에 따르면 아래와 같이 window기반으로 연산을 수행 할 수 있다. 이 연산은 동일 key를 가진 데이터를 대상으로 reduce 메서드를 수행하며 윈도우 단위로 읽다 보니 이전 데이터를 중복으로 읽는 경우가 생기는데 이 중복데이터를 제거해주는 함수를 사용할 수 있도록 제공하고 있다. 그 외에 연산은 링크를 참조하면 된다.
reduceByKeyAndWindow (func , windowLength ,slideInterval , [ numTasks ])

- 데이터 저장
saveAsTextFiles()와 같은 RDD와 동일한 메서드로 저장할 수 있으며 접두어 + 시간 + 접미어 형태로 저장되며 해당이름의 디렉토리가 생성되어 디렉토리내에 저장된다.
- 체크 포인트
마지막으로 성공했던 지점으로 복원하기 위하여 체크포인트를 지정해놓을 수 있다. 하지만 해당 상태를 외부 저장소에 매번 저장해야하므로 성능을 고려해야함

- 캐시
반복적으로 사용되는 데이터를 효율적으로 다룰 수 있도록 캐시 기능을 제공하며 리니지 정보처럼 처리 과정에서 손실된 데이터를 복원하는데에 사용되기도 한다. (체크포인트와 다른점은 캐시는 어플리케이션 종료시 사라진다는것)
Structured Straming
Spark 2.0부터 도입되었으며 SparkSession으로 생성되고 처리할 때 중복 데이터를 관리하기 위하여 time stamp를 도입하였다. 아래 그림에서 보면 알 수 있지만 DStream을 사용하지 않고 새로운 데이터를 row단위로 계속해서 쌓는다.
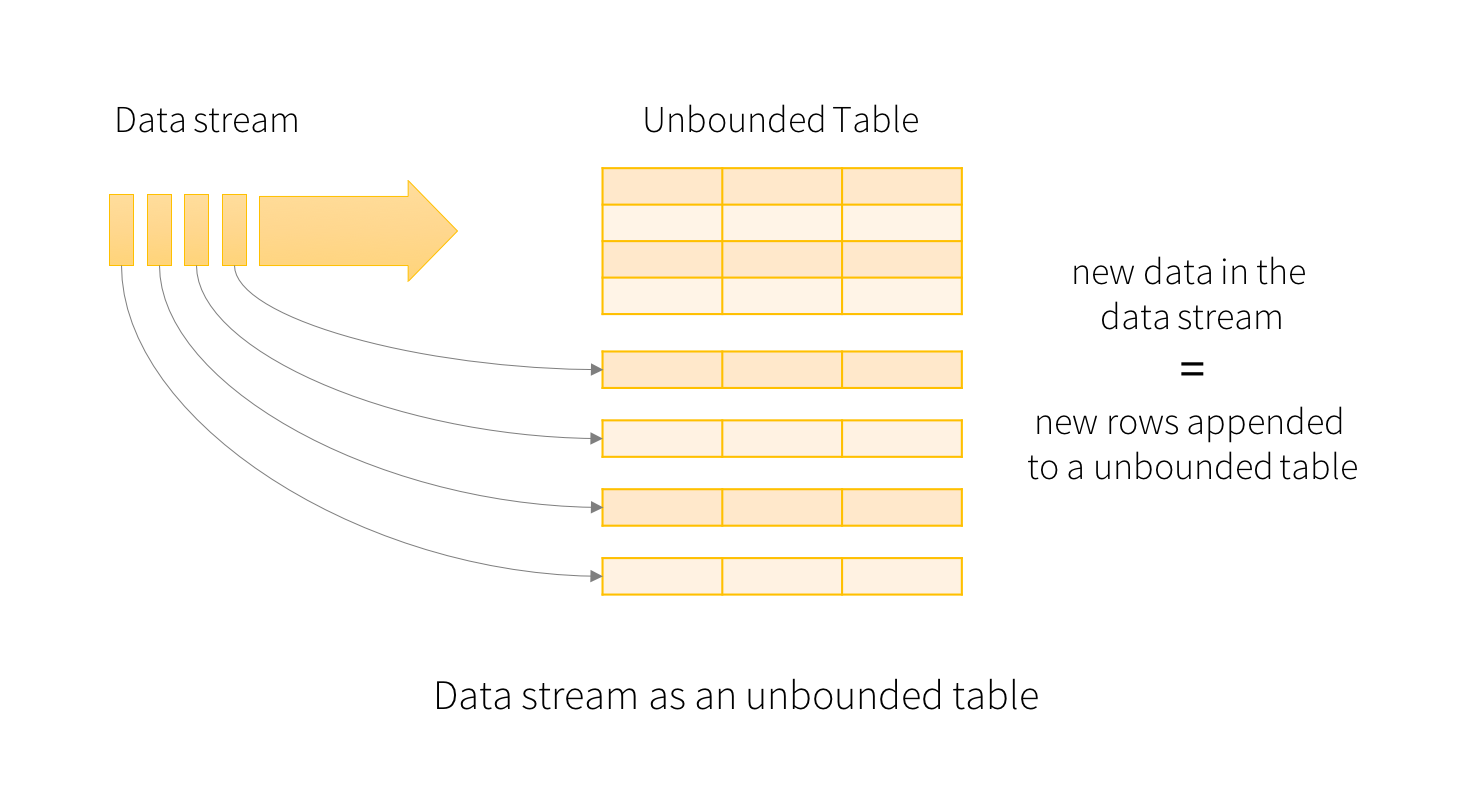
출처 : spark 공식 사이트
새로운 행이 추가되면 데이터가 쌓인 테이블을 업데이트 될텐데 이럴 때마다 결과 행을 외부 싱크(외부 저장 장치)에 기록해야한다.

출처 : spark 공식 사이트
이 때 다음 3가지의 모드로 출력을 정의 할 수 있다.
완료
업데이트 된 전체 결과 테이블이 외부 저장소에 기록
저장소 커넥터에서 어떻게 쓰기를 처리할지 결정함
추가
마지막 트리거가 기록 된 이후 결과 테이블에 새행만 추가함
기존행이 변경되지 않아야하는 조건에서만 적용
업데이트
마지막 트리거 이후 결과 테이블에서 업데이트 된 행만 외부저장소에 기록(spark 2.1.1.부터 사용ㅇㅋ)
쿼리에 집계가 포함되어 있지 않으면 추가 모드와 같음
- 예제를 따라해보자
한쪽 터미널에서 nc -lk 9999명령어를 쳐놓고..
아까와 같이 spark설치경로 아래에 있는 예제를 실행하면 아래와 같이 프로그래스바가 진행되고

이렇게 결과가 출력된다. ( 뭐라고 엄첨 나오는데 그럴땐 spark Info를 꺼보자 http://weejw.tistory.com/203 )

이 과정을 그림으로 살펴보면 아래그림과 같다. 이전 데이터와 지금 들어온 데이터를 함께 해서 incremental 쿼리를 수행한다.Structured Streaming은 전체테이블을 구체화하지 않고 사용 가능한 최신데이터를 읽어 처리를 하며 결과를 업데이트하는 데 필요한 최소 중간 상태 데이터만 유지한다.

출처 : spark 공식 사이트
윈도우 연산
structured streaming도 window 연산이 가능하다. 똑같이 간격과 윈도우 크기를 설정하고 추가적으로 데이터가 발생한 시간을 timestamp로 관리하여 추가하였다.

출처 : spark 공식 사이트
시간으로 관리했을 때 "두 시각의 차이가 많이 날 경우 처리에 포함을 시켜야하는가?" 를 고민하게 된다. 이럴때 이벤트 발생시각(데이터 발생)을 기준으로 워터마크를 설정해서 오래된 데이터는 버린다.
(가장 최근에 발생한 이벤트 시각 - 사용자가 설정한 이벤트 유효기간) < 해당 이벤트 발생 시각

워터마크 생성은 아래와 같이 한다.
val windowedCounts = words.groupBy(window($"timestamp", "10 minutes", "5 minutes"),$"word").count()스트리밍 쿼리
실제로 작업을 시킨 후 결과를 출력하거나 저장하는 쿼리로 DataStreamWriter를 이용하는데 데이터셋의 writeStream()메서드를 통해 사용한다. 사용할때는 다음 중 하나 이상을 지정해야한다.
1) 출력 싱크의 세부 정보 ex.형식,위치
2) 출력 모드
- Complete : 전체 데이터 저장
- Append(default) : 이전 결과를 제외한 새로운 결과만 저장
- Update(spark 2.1.1.부터) : 이전 결과를 제외한 업데이트된 결과 테이블의 행만
3) 트리거 간격
4) 체크 포인트 위치
5) 질의 이름
위지원데이터 엔지니어로 근무 중에 있으며 데이터와 관련된 일을 모두 좋아합니다!. 특히 ETL 부분에 관심이 가장 크며 데이터를 빛이나게 가공하는 일을 좋아한답니다 ✨
'2018년 > spark' 카테고리의 다른 글
GraphX ~그래프 연산 (0) 2018.04.03 GraphX ~그래프 생성까지 (0) 2018.04.02 spark info좀 꺼보자 (0) 2018.02.28 RDD(Resilient Distributed Datasets) (0) 2018.02.27 [Spark] :: 구조 및 동작 과정 [이론] (0) 2018.01.17
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
