
-

GraphX는 스파크의 서브 모듈로 대용량 데이터의 분산 및 병렬 그래프 처리를 지원합니다.

그래프 데이터는 Vertex와 Edge로 이루어져있습니다.

시작하기 전에 spark를 실행시키고 해봅시다. 필요한 친구들을 import 해주면 세팅은 끝..

GraphX 공식 사이트에 보면 기본 알고리즘을 제공합니다. 우리는 이를 이용하여 데이터 전처리부터 분석단계까지 스파크 기능을 사용할 수 있습니다.

그래프는 다음과 같이 4가지의 형태를 가지고 있습니다.

속성그래프 : 각 vertex와 edge가 연관된 속성을 가지고 있는 방향 멀티 그래프
속성 그래프에 대한 예제를 실행해보겠습니다. VertexID를 각 Vertex를 식별할 key로 가집니다.
*scala에서 변수 선언시 ':'는 ':'뒤에 명확한 데이터 타입을 지정해줍니다.

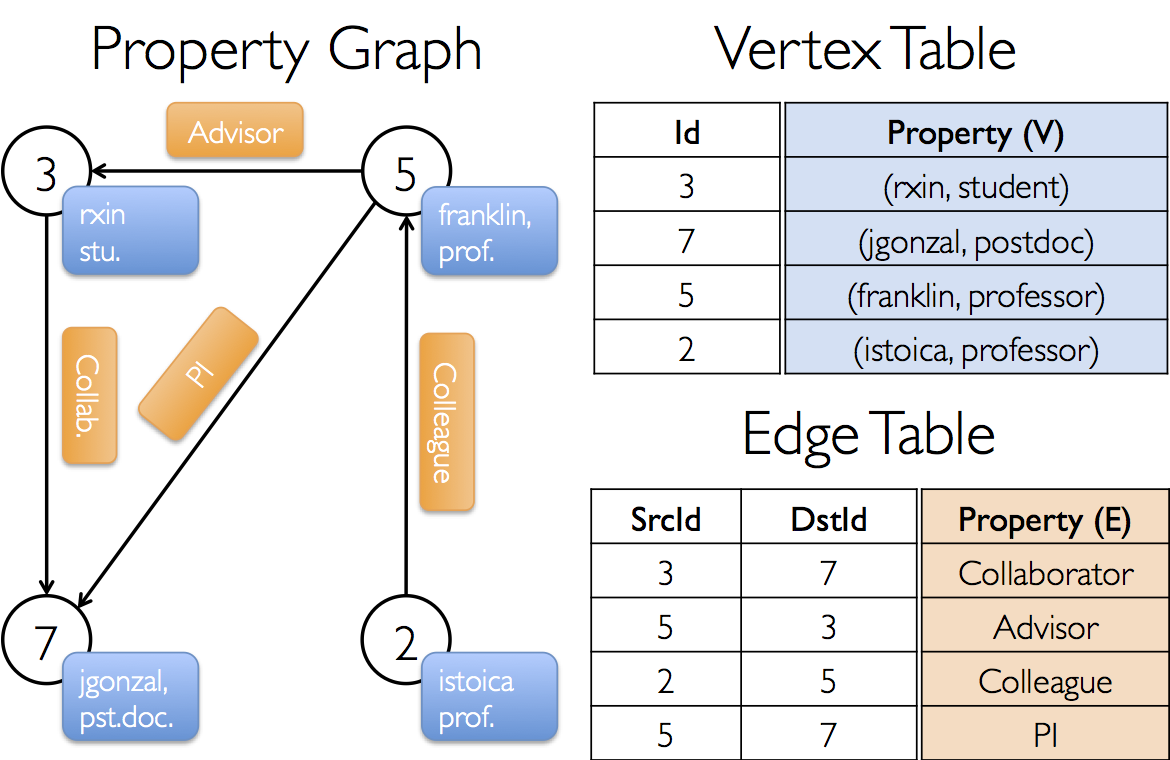
그림출처 : https://spark.apache.org/docs/latest/graphx-programming-guide.html#property-operators
예제를 따라해보자
1) 우선 각 Vertex에 대해 생성한다.
key와 속성이
(3,("rxin","student"))
(7,("jgonzal","postdoc"))
(5,("franklin","prof"))
(2,("isoica","prof"))
이므로 아래와 같은 코드로 생성 할 수 있다

2) 두번째로는 Edge에 대해 생성한다.
각 Vertex의 관계를 보면
3 -> 5 , "advisor"
3 -> 7 , "collab"
2 -> 5 , "colleague"
5 -> 7 , "pi"
이므로 아래와 같은 코드로 생성 할 수 있다

마지막으로 누락된 사용자와 관계가 있을경우를 대비해 default를 정해주고 마지막으로 graph를 생성한다.

생성된 그래프에는 아래와 같이 질의를 처리할 수 있다.

데이터 타입
1) RDD : GraphX는 RDD를 기반으로 동작
그래프를 구성하는 Edge와 Vertex를 각 RDD로 관리하며 Vertex로 구성된 RDD와 Edge으로 구성된 RDD의 조합을 그래프라고 한다.
2) VertexID : 모든 Vertex는 식별ID를 가지며VertexID라는 type을 사용(scala의 Long Type)
3) 꼭지점 : ID(VertexID type)와 속성으로 구성된 Tuple
ex. ID:3,속성("weejw","위지원") >> (3,("weejw","위지원"))
4) Edge:org.apache.spark.graphx.Edge class에 존재 ☞API 주소☜

5) EdgeTriplet : Edge와 Vertex 정보를 한번에 확인할 수 있도록 모아놓은 데이터타입


아래와 같이 표현할 수도 있다.

6) VertexRDD
그래프 처리에 특화된 기능을 추가하기 위해 VertexRDD사용( 일반 RDD를 사용하는것도 가능하긴 하다. )

7) EdgeRDD

8) Graph
내부적으로는 VertexRDD,EdgeRDD, 데이터 파티셔닝 및 분산처리를 위한 라우팅 테이블 관리

그래프 생성은 아래 메서드를 사용하여 할 수 있습니다.

생성해봅시다. 아래와 같이 VertexRDD와 EdgeRDD를 생성합니다.

그럼 아래와 같이 3가지 방법으로 그래프를 생성할 수 있습니다.

마지막 g3를 보면 3번째 파라미터가 더해졌습니다. 이를 자세히 보자면
PartitionStrategy는 동일한 Edge를 동일한 파티션에 두어 중복을 방지하기 위한 목적으로 그래프 edge ㄷ데이터에 대한 피션 정책을 결정합니다.
- RandomVertexCut : Edge에 포함된 두 꼭지점 ID를 tuple로 만들고 tuple의 hash값을 이용해 파티셔닝
-->소스 vertex와 목적지 vertex가 같은 edge라면 같은 파티션
- CanonicalRandomVertextCut : 위와 같은 방법으로 파티셔닝을 수행
-->소스와 목적지 정보 고려하지 않고 크기가 오름차순으로 튜플을 생성하기때문에 관계의 방향에 상관없이 Vertex가 같으면 동일한 파티션
- EdgePartition1D : 소스 vertex ID만 이용해서 파티셔닝
- EdgePartition2D : 두 vertex ID값을 기반으로 희박 인접 행렬을 구성해서 파티셔닝
'2018년 > spark' 카테고리의 다른 글
오랜만에 만져보는 spark scala코드 (0) 2018.07.18 GraphX ~그래프 연산 (0) 2018.04.03 spark info좀 꺼보자 (0) 2018.02.28 Spark Streaming,Structured Streaming (0) 2018.02.27 RDD(Resilient Distributed Datasets) (0) 2018.02.27 - RandomVertexCut : Edge에 포함된 두 꼭지점 ID를 tuple로 만들고 tuple의 hash값을 이용해 파티셔닝
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
