
-
원본 논문
Wide & Deep Learning for Recommender Systems
Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are
arxiv.org
무엇을?
Wide 선형 모델 + DNN 모델 공동 훈련이 가능한 wide&deep learning 제시
선형 모델: y = w^Tx+b
필요성
입력값이 희소한 대규모 회귀 분석과 분류 문제에 비선형 변수 변환을 적용한 일반화 선형 모형을 흔히 사용한다. 그래서 일반화가 필요한데
기존 일반화를 진행할 때 단점이 몇가지 존재해서, Generalization + Memorization 의 장점을 결합할 필요가있다.
장점
- Memorization: Cross-product feature transformation 을 이용해 wide한 집합으로 가능 -> 효과적이고 해석가능
- Generalization: DNN 은 적은 횟수의 feature engineering을 통해 저차원 Dense한 임베딩을 통해 일반화 가능
✔️ Memorization: 동시에 빈발하는 품목 또는 변수를 학습하고 과거 이력에서 이용 가능한 상관관계를 뽑아내는 작업, 일반적으로 더 topical 그리고 directly relevant to the items on which users have already perfomed actions 함
✔️wide 선형 모델은 Cross-Product Feature Transformations를 사용해 Sparse Feature Interactions를 효과적으로 Memorize가능
✔️ Generalization: 이행성(transtivity)에 기반하고 과거에 결코(never) 또는 거의(rarely) 발생하지 않은 새로운 변수 조합을 탐구,Memorizaiton과 비교하여 추천 아이템의 다양성이 증진.
✔️DNN은 low dimensional embedding을 통해 새로운 Feature Interactions를 Generalize할 수 있음왜 결합하는가?
- wide의 일반화는 feature engineering이 많이 필요
- 임베딩을 이용한 DNN은 sparse하고 high-rank일 때 관련 없는 추천을 할수도 있음
목적
- wide 선형학습과 DNN 동시 학습으로 Generatlization + Memorization 장점을 결합해 성능 극대화, 아래 그림과 같이 결합함

방법론
1. wide component
1) binary feature인 경우, cross-product transformation의 모든 constituent feature가 1이여야 1 else 0

cross-product transformations: Cki is boolean variable, 만약에 i번째, fueatrue가 k번째 transformaion의 일부이면 1 else 0 2. deep component
1) 범주형 = original feature string
2) sparse, high-dimensional categorical feature = low dimensinal and dense real-valued vector로 변환(embedding vecotr, usually 0~100 dimension): 처음엔 무작위로 초기화된 후 이 후 모델의 손실 함수를 적게하는 방향으로 갱신
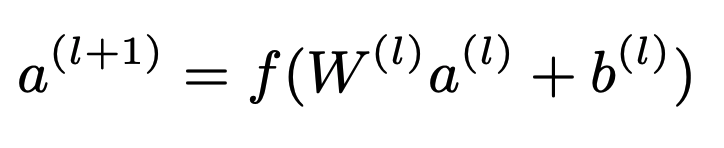
3. joint training of wide & Deep Model
wide, deep 결과물은 출력한 로그 오즈 가중치 합계(A weighted sum of their ouput log odds)를 예측치로 사용, 공동 훈련을 위해 하나의 공통 로지스틱 손실 함수에 입력.
✔️ odds: 도박에서 얻을(pay off) 확률과 잃을(stake) 확률의 비율을 뜻하는 영어단어, 실패비율 대비 성공비율을 설명하는 것.
p/(1-p)
✔️ log odds: logit은 ‘logistic’ 과 + ‘probit’ , odds에 자연로그 씌운 것
자연로그 ln(p/(1-p))
odds는 그 값이 1보다 큰지 아닌지로 결정의 기준
logit은 그 값이 0보다 큰지 아닌지로 결정의기준
[0,1] 범위인 확률을 [−∞,∞] 범위로 넓히므로 딥러닝에서는 확률화되지 않은 결과를 로짓이라고 함.공동훈련은 mini-batch stochastic potimaization을 이용해서 두 컴포넌트의 결과물 gradients를 동시에 back propagating 으로 수행.
옵티마이저는 Deep-Adagrad, wide는 L1 정규화를 따르는 Follow-the-regularized-leader(FTRL) 사용.
구현
- 노출한 앱 설치:1 else 0
- 정한 최소회수 이상 생성된 어휘로 저장
- 정규화는 연속적인 실수 값 변수는 변숫값 x를 누적 분포 함수 n분위수로 나뉜 누적 분포함수 에 맵핑해 [0, 1]로 맵핑

훈련
- Deep component: Impression application과 user가 설치한 application의 cross-product transformations로 구성
- Wide component: 32차원의 embedding vector가 각 범주형 변수에 대해 학습
- Dense feature를 이용한 모든 embedding을 concatenate해 대략 1,200 차원의 Dense vecor 도출
- 연결한 벡터를 3개의 ReLU 층으로 전달하고
- 마지막으로 로지스틱 출력 단위로 전달

- 새로운 데이터 셋에 대한 학습시간을 줄이기 위해 임베딩과 이전 모형의 선형 모형 가중치를 사용하여 새 모형 초기값을 설정하는 식의 웜 스타트 시스템을 구현
사용해보기
알아봤으면 써봐야징 !!!! 당연히!!!
keras에서 제공한다.
원래 튜토리얼 🦆은 사망했다.tf.keras.experimental.WideDeepModel | TensorFlow Core v2.4.1
Wide & Deep Model for regression and classification problems.
www.tensorflow.org
전체 코드는 아래에 저장해두었다 😎 없는게 없는 파이썬의 세계.. 구현? 어림없지~
weejw/Study_Code
Contribute to weejw/Study_Code development by creating an account on GitHub.
github.com
REFERENCES
github.com/kaitolucifer/wide-and-deep-learning-keras
colab.research.google.com/gist/ravikyram/db71114bed69f93906e38c5435d5ba56/untitled637.ipynb
github.com/tensorflow/tensorflow/issues/46719
haje01.github.io/2019/11/19/logit.html
opentutorials.org/module/3653/22995
aldente0630.github.io/data-science/2018/04/28/wide_and_deep_learning_for_RS.html
'2021년 > 개발공부' 카테고리의 다른 글
[논문 정리] A Contextual-Bandit Approach to Personalized News Article Recommendation (0) 2021.04.17 오늘부터 나도 인싸! 인터넷 친구만들기 😎 (0) 2021.04.15 쿠버네티스 예제: mongodb+kubernetes (0) 2021.04.12 Python decorator (2) 2021.04.12 쿠버네티스 기초학습[클러스터 생성, 앱 배포] (0) 2021.04.06
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
