
-
본사에 복귀를 했고, 매일 oracle 교육을 듣게되었다. .. 나는 들으면서 난이도가 꽤 높다고 느끼는데 다른 분들은 아닌가보다..ㅠㅠ분발해라 똥멍청아

리터럴 쿼리
리터럴 쿼리: select * from table where name="위지원"
바인딩 쿼리:select * from table where name=:name
교육해주신 분의 말씀으론 튜닝의 가장 우선순위 중 하나가 이 리터럴 쿼리를 없애는 것이라고 한다.
select * from table where name in (select name from tableB); 와 같이 작성하면 동적쿼리라 불리며 앞서 말한 바인딩 쿼리이다.
둘의 가장 큰 차이는 리터럴 쿼리는 입력 될 때마다 새로운 쿼리로 인식하고 바인딩 변수는 쿼리 자체는 한 번 컴파일된 이후 재사용이 가능하다는 것이다. 그래서 리터럴 쿼리는 하드 파싱의 빈도가 높다. (바인딩 변수 빼고) 이로 인해서 데이터베이스 부하를 줄일 수 있다.
*대소문자, 공백, 라인도 구분해서 새로운 쿼리로 인식한다.
또한, 오라클의 Shared pool에 구문 파싱 정보를 각각 생성하기 때문에 사용성이 비효율적이다.
단, 데이터 분포도가 명확하여 이를 이용하는 경우에는 Literal SQL이 더 나을 수 있다고 한다.
하드 파싱: 이전에 실행 된 적 없는 쿼리로, 오라클의 Shared Pool/Library Cache에 없어서 전부 다 파싱
소프트 파싱: 이미 Cache에 존재해 재사용Index
Reverse Key Index
키 '값'을 역으로 변경, 예를 들어 인덱스 키칼럼 값이 123이면 321로 변경. 인덱스 값이 증가하면 오른쪽 리프노드에만 데이터가 증가하는 현상이 일어난다(경합 발생). 이 현상을 방지하기 위함이다.
인덱스가 많으면 데이터를 삭제, 업데이트, 입력 할 때마다 인덱스를 생성하기 때문에 좋지 않다. 즉 테이블 갱신 작업 시 오버헤드 발생이 크다.
null은 index를 탈까?
오라클은 null은 index를 타지 않는다. 그 외에 MyISAM, InnoDB, BDB, MEMORY 엔진을 사용할 경우는 탄다고 한다.(출처:
FK는 index를 탈까?
때에 따라, DB에 따라 다르다고 한다.
Does MySQL index foreign key columns automatically?
Does MySQL index foreign key columns automatically?
stackoverflow.com
FK를 이야기하니까 추가적으로 적고싶은 말이 있어서 몇 자 더 적어본다.
실무에서는 FK를 잘 쓰지 않는다고 한다. 학교에서 그렇게 주구장창 FK란 무엇인가? FK의 특징은? 하면서 배웠지만 실상 잘 사용하지 않는다는 이야기를 듣고 나는 무척 의아했다.
이 말을 들은 곳은 데이터엔지니어 방이었는데, 거기서 하셨던 말씀으로는 복잡성 증가, 유지관리 어려움 등을 이유로 꼽았다.
좀 더 자세하게 보자면,
"참조될 키는 우선적으로 먼저 만들어져있어야 한다"
"CASCADE 설정이 된 상태에서 실수로 쿼리를 날렸을 경우 전체 데이터 변경, 정합성 문제 발생 최소화"
"CASCADE OPTION을 위한 무결성 검증으로 인한 성능 저하"
"차후 구조 변경의 편의성"
등의 문제점을 꼽고 이로 인해 외래키 사용을 지양하는 것이다.
인덱스를 안 타는 경우는 무엇이 있을까?
이번에 sql 관련 프로젝트를 하면서 이와 관련해 참 많은 실수를 하고 참 많은 것을 얻었다. 결과적으로는 쿼리 플랜을 잘 보고 인덱스를 타는지 여부에 따라 쿼리를 잘 짜는 것이 중요하다.
1. 컬럼 값에 변형이 들어가는 경우
팀장님이 절대 하지 말라고 하셨던 것이다. 비단 인덱스뿐이 아니라 그냥 조건절에서 기본 데이터 변형을 할 생각 말라고 하셨다. 데이터가 크면 클수록. 예를 들어 1000만 row라면 변형을 1000만 번 해야 하는 것이니까..(ㅠㅠ)
예: select * from table where to_date(date_col,'yyyymmdd')='20230104'
위와 같이 명시적으로 변형을 한게 아니어도 내부적으로 형변환이 일어날 수 있다. 예를 들어 아래처럼 column이 string형인데 숫자로 조건을 준 경우 내부적으로 형 변환이 일어나며 인덱스를 타지 않는다.
예:select * from table where string_col=123
2. select * from table where name="%지%" 또는 name="%지"
3. where 절에 부정문 사용
4. Optimizer 맘대로..
이번에 쿼리 짜면서 플랜을 여러 번 봤다. index를 지정해줌에도 불구하고 인덱스를 안 타고 optimizer 맘대로 풀스캔을 타는 경우도 있었고, 반대의 경우도 있었다.
Oracle의 Index 탐색 방식
index 탐색 방식에는 아래 5가지가 존재한다.
1. Index Unique: 1개의 건이 필요한 경우, pk에 default로 생성
2. Index Range: 말 그대로 범위 스캔 where >~
3. Index Full: 전체 다 스캔!
* table full scan은 multi-block read, index full scan은 single block read
4. Index Fast Full: mutiblock read 가능, 또한 index full이 논리적 order 결과를 받는다면 fast는 물리적 저장 구조 순서임 그러므로 빠를 수밖에 없음!
5. Index Skip: 다중 컬럼 인덱스에서 첫 번째가 아닌 칼럼을 조건 절에서 사용할 때 활용, 후행 칼럼의 고윳값 개수가 많을 때 효과적
parition
인덱스 이야기를 하니까 파티션 인덱스에 대해 추가적으로 생각이 나서 찾아보려 한다.
파티션 테이블은 Local, Global Partition Index가 존재한다.
파티션 테이블은 파티션 키가 있다. 이 파티션 키로 테이블이 분할되어 있다. 파티션 키를 인덱스 키 컬럼으로 지정할 수 있는 경우가 로컬 인덱스, 사용하지 못하는 경우가 글로벌 인덱스를 만드는 것이다.
글로벌 인덱스의 Unusable Status
인덱스가 특정 상황이나 operation에 의해 사용하지 못하는 상태를 의미하며, Index Rebuild가 필요하다. 본 상태가 되는 경우와 해결 방법은 이 링크를 참고하자.
Index skip scan이 발생하는 조건
1) index의 선두 컬럼이 filter 조건에 포함되지 않거나 가공 됨
2) index의 중간 컬럼이 filter 조건에 포함되지 않음
3) index 선두 컬럼의 ndv가 소수인 경우 또는 후행컬럼의 ndv가 다수인 경우
*NDV (Number of Distinct Value): 유일하게 구별되는 Column값의 개수
인덱스 튜닝을 할 때 최대한 1번에 가까운 스캔을 할 수 있도록 튜닝을 하는 것이 좋다.
1. index range, unique scan
2. index skip scan
3. index concatenation
4. index full scan
5. table full scan
oracle의 memory 구조
아래는 oracle 공식 사이트에 나와있는 oracle의 메모리 구조이다.
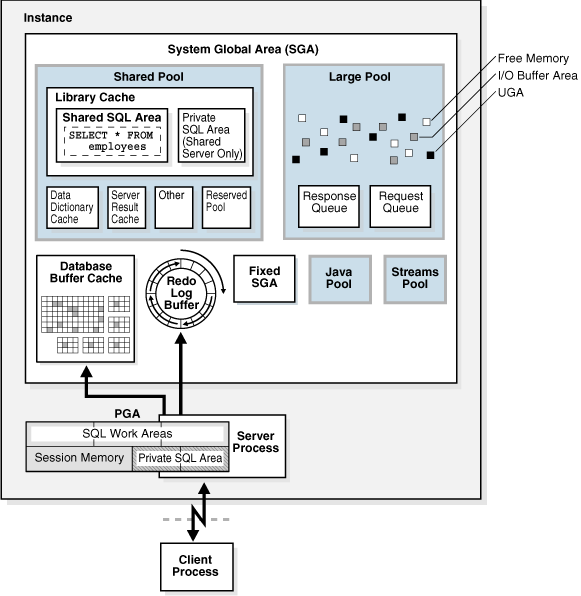
https://docs.oracle.com/database/121/CNCPT/memory.htm#CNCPT7778 위 그림을 보면 알겠지만 크게 PGA(Program Global Area)와 SGA(System Global Area)로 나뉜다.
PGA(Program Global Area) SGA(System Global Area) 유저 요청 작업 처리에 사용 되는 영역 디스크로부터 읽은 데이터를 메모리에 적재해 READ/WRITE/UPDATE/DELETE 시 사용 되는 영역 PGA
서버 프로세스나 백그라운드 프로세스가 시작 될 때 갖는 나만의 영역
- 정렬공간, SQL 작업공간으로 이루어져 있고 비공유 영역으로 private global area라고도 불리운다.
- 유저 프로세스 세션 정보 ,cursor state, stack space(바인드 변수 저장)가 존재한다.
SGA
- Shared Pool에는 SGA 관리 메커니즘이 저장되어있다.
- SQL, Data dictionary cache를 활용해 실행 계획을 만들고 이 pool에 서 공유
- 캐시 영역이 있다.
- 라이브러리 캐시: 유저가 생성한 SQL, 실행 계획을 저장
- 데이터 딕셔너리 캐시: row 캐시, Oracle Object 정보를 저장
- 데이터 버퍼 캐시: LRU 로 관리, 디스크에서 읽어온 데이터를 저장(Disk I/O 영향도를 줄이는 것이 목적)
- Redo Log Buffer: 데이터 변경에 대한 로그 저장
- DBWR(Database Writer): 데이터 버퍼 캐시 > 디스크
- LGWR(Log Writer): 로그 버퍼 > 로그 파일
- Large Pool: Parallel Query 메시징, 대용량 메모리 할당 필요 시 사용
- Java Pool: Oracle DB에서 JAVA를 이용할 수 있도록 만들어진 영역
오라클의 데이터 저장 구조
오라클 저장구조를 살펴보면 가장 상단엔 DataBase가 있고 이는 아랙 그림처럼 논리적 단위로 구성되어있다.
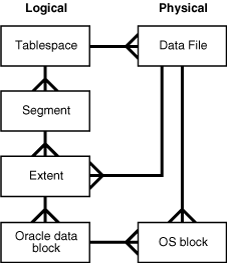
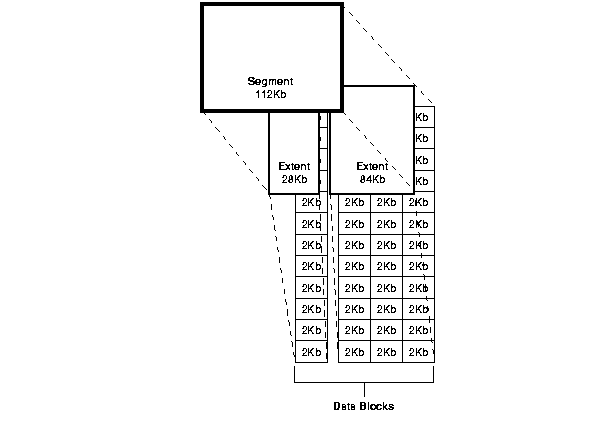
https://docs.oracle.com/cd/E18283_01/server.112/e16508/logical.htm - Block: 하나 이상의 OS 블럭으로 구성된 Data가 저장되는 최소의 구조단위 또는 I/O의 최소 단위이다.
- Extent: Segment에 할당 된 연속된 Block의 집합
- Segment: Extent의 집합
- Tablespace: tablespace와 datafile은 1:1 의 관계이다.
참고
더보기http://www.gurubee.net/lecture/1101
https://debaeloper.tistory.com/49
https://it-techtree.tistory.com/entry/oracle-database-memory-component
https://before-midnight.tistory.com/13
https://myjamong.tistory.com/237
https://jack-of-all-trades.tistory.com/181
https://ivvve.github.io/2020/07/08/server/rdb/is-fk-indexed/
http://www.gurubee.net/lecture/2959
https://www.slideshare.net/topcredu/15-literal-sql-amp-bind-variable-sql
'2023년' 카테고리의 다른 글
devfest 2023 in songdo (0) 2023.12.10 centOS7 + Superset + Oracle (0) 2023.03.02 Python OCR (5) 2023.03.02 Superset 설치 메모 (0) 2023.02.07 Data Mart, Data Warehouse, Data Lake (6) 2023.01.13
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Engineer가 되는 그날까지🏃♀️ 화이팅!
