
-
후.. 발표가 있다 😥
오늘은 아래 3가지를 알아보려 한다.
- Data Mart
- Data Warehouse
- Data Lake
위 3종 세트는 저장되는 데이터의 특성/활용에 따라 다르게 사용된다. 쉽게 살펴보자면! Data Lke => Data Warehouse => Data Mart 순으로 가공이 된다.

https://www.sqlhammer.com/what-is-a-data-lake/
OLAP와 OLTP
들어가기에 앞서 OLAP와 OLTP를 알아보고자 한다. 그 이유는 오늘 알아볼 3종 세트에 저장되는 데이터들이 OLAP를 위한 데이터이기 떄문이다.
- OLTP(Online Transaction Processing); 복수의 사용자의 트랜잭션 요청을 DB서버에서 처리하고 결과 RETURN(처리)
- OLAP(Online Analytical Processing): DW에 저장되어 있는 데이터를 분석하고 인사이트를 제공하는 처리방법(분석)
쉽게 말하면 INSERT,UPDATE,DELETE,SELECT 와 같은 처리 자체는 OLTP, 사용자의 목적에 맞게 데이터를 분석하는 것을 OLAP라고 할 수 있다. https://too612.tistory.com/511 게시글에 표로 정리 되어 있다. 이를 통해 OLTP는 실시간 비즈니스 활동 지원, OLAP 는 과거의(이미 적재 된) 데이터에 대한 평가, 분석 용도로 쓰인다는 것을 알 수 있다.
DATA LAKE

https://learn.microsoft.com/ko-kr/azure/architecture/data-guide/scenarios/data-lake 자, 다시 돌아와서 이제 왜 3종 세트가 OLAP를 위한 데이터를 저장하다는 것인지 알았을 것이다. 모두 어떠한 '목적'을 가지고 각각의 형태로 저장되어 있는 것이기 떄문이다.
Data Lake를 한 줄로 말하자면 "목적 없이 일단 저장해놓은 원천 데이터 저장소" 이다. 위키에서는 다음과 같이 정의하고 있다.
"A data lake is a system or repository of data stored in its natural/raw format,[1] usually object blobs or files."
또한 어원에 관해서는 Pentaho라는 BI 회사의 CTO인 James Dixon이라는 분이 처음 언급했다고 한다.
"Coined by Pentaho CEO James Dixon in 2010."
"If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples. (출처: https://wiki.atlan.com/data-lake/)"
또한 기존의 Mart로 대응하지 못하는 문제점을 해결하기 위해 Lake를 사용하였다.
전통적인 BI 프로세스는 데이터 웨어하우스를 구축하는 데에 80% 이상의 시간을 소요하기도 했다. 그럼에도 불구하고 잘 만든 데이터 웨어하우스는 그 당시 선택할 수 있는 가장 효과적인 데이터 관리 방법론이었다.
하지만 2000년대 후반에 들어서면서 데이터 웨어하우스로는 대응할 수 없는 문제들이 일어나기 시작했다. 가장 큰 문제는 기업이 수집하는 데이터의 양과 종류가 빠르게 증가하고 있다는 점이었다. 더군다나 이렇게 모아둔 데이터가 모두 유용한 가치를 가지고 있다고 보기도 어려웠다. 구축하는 데에 많은 공수를 필요로 하는 데이터 웨어하우스로는 빠르게 증가하는 데이터에 대응할 수 없고, 기껏 구축해놨더니 무가치한 데이터로 판명될 위험이 있었다.
그래서 기업들은 데이터의 종류를 가리지 않고 원시 데이터(raw data) 그대로 저장하는 데이터 레이크를 구축하기 시작했다. 저장하는 과정에서 별다른 처리를 하지 않기 때문에 빠르게 증가하는 데이터들을 신속하게 담아둘 수 있었다. 또한 데이터 레이크의 특징 중 하나인 데이터를 저장할 때는 스키마를 정의하지 않고(schemaless) 우선 모아두었다가, 해당 데이터가 필요해서 읽어올 때 스미카를 정의하는 것(schema on read) 역시 쓸모있는 데이터에만 공수가 들어간다는 점에서 매우 효과적이었다.
출처 : 아이티데일리(http://www.itdaily.kr)레이크는 비정형, 정형, 반정형 등 다양한 형태의 데이터가 저장되는 곳이다. 내가 처음 배웠을 때는 넘쳐나는 데이터들을 목적은 일단 제처두고 빠르게 수집하기 위한 목적으로 사용된다고 했다. 그러나 요즈음에는 시스템이나 회사마다 그 이유가 달라 명확히 정의할 순 없다고 한다. 그래도 궁극적인 목적은 '저장' 이다. 그래서 가공되지 않은 원천 데이터, 즉 RAW DATA가 저장된다.
위에서 언급한 듯이 "빠르게 수집", "비정형, 반정형 등 다양한 형태의 데이터 저장" 의 목적 달성을 위해 일반적으로 File Sotre, NoSQL을 사용한다. 데이터가 얼마나 많이 저장될지 알 수 없기때문에 구축할 때 많은 것을 고려해야한다. 클라우드가 보편화 된 요즈음은 클라우드로 구축을 많이 한다고 한다.(쓰는 만큼만 비용이 소모되고 탄력성, 확장성 또한 우수하기 때문에)
왜 DATA LAKE를 사용할까? (장점)
- 비정형(특히 이 종류의 데이터가 현실에선 더 많지 않은가?), 반정형 데이터를 모두 저장한다. 정말 많은 종류의 데이터가 생성되는 요즘 데이터 레이크는 효과적인 저장소임에 틀림없다.
- 의사결정에 도움을 준다. 기업에서 의사결정을 위해 단 한개의 소스만을 사용하는 경우는 드믈다. 이 때, 온 종류의 데이터가 저장되어 있는 레이크는 효과적인 의사결정의 근거가 될 수 있다.
- 싸다. Data Warehouse에 비해 저렴한 가격이다. 그 이유는 Data Warehouse는 스키마 정의, 인덱싱 등 준비가 필요하고 또 Data Lake에 비해 SW나 HW 자체가 비싸다고 한다.
- 데이터 접근성이 높아진다. 나는, 데이터를 분산 저장 관리하는 것이 더 효과적이고 타당하고 생각했었다. 그러나 여기저기 데이터 소스가 흩어져 있는 경우 각각의 시스템에 접근하고 수집해야하기때문에 꽤나 어려움이 따른다고 한다. 이 때문에 한 곳에서 모아서 데이터를 관리하는 경우 전사 수준에서의 데이터 이해도와 데이터 접근성의 증가를 만들어낼 수 있다.
- https://wiki.atlan.com/data-lake/ 에서 언급한 내용에 의하면 Lake는 Mart에 비해 유연하고 저렴하며 안전하고 확장성이 높다는 장점으로 인해 사용한다고 한다.
어디서 DATA LAKE를 사용할까?
- 재미난 사실은 Data Warehouse는 비즈니스 분석가가 주로 사용하고, Lake는 데이터 사이언티스트가 주로 사용한다. 그래서 Lake는 일반적으로 데이터 분석/기계 학습에 사용된다.
- 특별한 제약이 없이(스키마 정의 등) 저장을 하므로, 이벤트 스트리밍/IOT 시나리오에서도 자주 쓰인다고 한다.
그 외에 https://learn.microsoft.com/ko-kr/azure/architecture/data-guide/scenarios/data-lake 에 의하면 다음과 같은 사용 사례가 있다.
- 클라우드 및 IoT 데이터 이동
- 빅 데이터 처리
- 분석
- 보고
- 온-프레미스 데이터 이동
단점은 무엇일까?
우선, 앞서 지속해서 언급했듯이 '가공없이 일단 저장' 이기 때문에 주기적인 관리가 필요하다.
- Dark Data(사용하지 않는 불필요한 데이터): 주기적인 데이터 소멸 필요
- Data Swamp(사용자가 엑세스할 수 없는 Data Lake): 지속적인 Lake 유지 관리 필요, 데이터 거버넌스 관리
- 원시 데이터이기 때문에 다루는 데 큰 역량을 필요로 한다.=> 역량 부족으로 인해 Data Swamp가 될 수 있다.
* 데이터 거버넌스: 데이터의 보안, 개인정보 보호, 정확성, 가용성, 사용성을 보장하기 위해 수행하는 모든 작업(https://cloud.google.com/learn/what-is-data-governance?hl=ko)
다음으로 성능저하다. 워낙 방대한 양의 데이터를 저장하기 때문에 쿼리 엔진 성능 자체가 저하될 수도 있다. 또한 이런 저장소에 반복적인 접근도 쿼리 성능 저하에 영향을 끼친다. 특히 메타데이터로 인한 병목 현상 발생이 있을 수 있다.
마지막으로 보안문제이다. 모든 종류의 데이터를 한 저장소에 저장하기 행위는 데이터에 대한 보안을 취약하게 만들 수 있다.
Data Lake가 사라지고 있다?
오늘날 Data Lake는 아래와 같은 이유로 사라지고 있다고 한다..(ㅠㅠ)
데이터 레이크는 비정형 데이터를 모두 저장해야 한다는 전제 하에 구축되었기 때문에 점점 사라지고 있습니다. 일부는 데이터 웨어하우스에 저장되고, 일부는 데이터 레이크에서 상실됩니다. 이에, 데이터를 통합할 수 없게 되고 데이터 속도가 저하됩니다. 스토리지 시스템을 통해 단일 플랫폼에 데이터를 통합하는 것은 왜 이렇게 어려울까요? 각 애플리케이션이 데이터에 대한 서로 다른 요구사항을 가지고 있어 데이터 사일로가 급증하기 때문입니다. 스토리지에 대한 생각을 전환할 때입니다. (출처: https://www.purestorage.com/kr/knowledge/data-lake-vs-data-hub.html)
DATA WAREHOUSE
앞서 살펴본 LAKE와 다르게 WAREHOUSE는 '구조화 된', '목적이 있는' 데이터를 저장하는 저장소이다. 90년대 후반까지만 해도 운영-분석을 한 Database에 데이터를 저장해서 사용했다고 한다. 하지만 이 방식은 시대가 흐르면서 많은 문제점을 불러일으켰고, 이를 해결하기 위해 warehouse가 등장했다.(https://hyunie-y.tistory.com/42?category=916186)
단일 저장소의 문제점
- 운영과 분석이 동일 기준으로 데이터를 바라보지 않을 수 있다. 또한 운영과 분석에서 사용되는 형태나 저장되는 형태가 다를 수 있다.
- 단일 데이터베이스를 사용하는 것은 과부하로 인한 응답지연으로 이어진다.
또한 어원은 위키에 의하면 다음과 같다.
"Coined by IBM researchers Barry Devlin and Paul Murphy in 1988."
여러가지 저장소에서 목적에 맞게 데이터를 수집/통합하기 때문에 데이터 '창고'라는 의미에서 warehouse라는 이름이 붙어졌다고 한다.
앞서 살펴본 Lake와는 그림으로 볼 때 아래와 같은 차이를 갖는다.
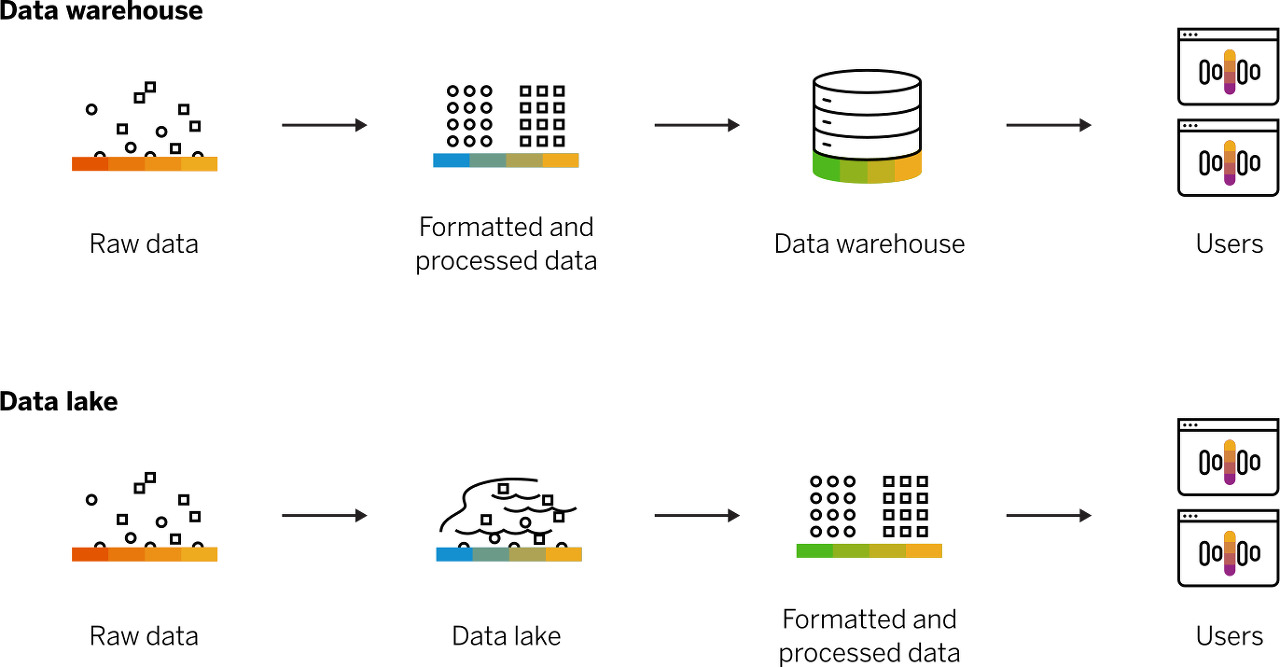
https://www.sap.com/korea/insights/what-is-a-data-warehouse.html 주요 구성 요소
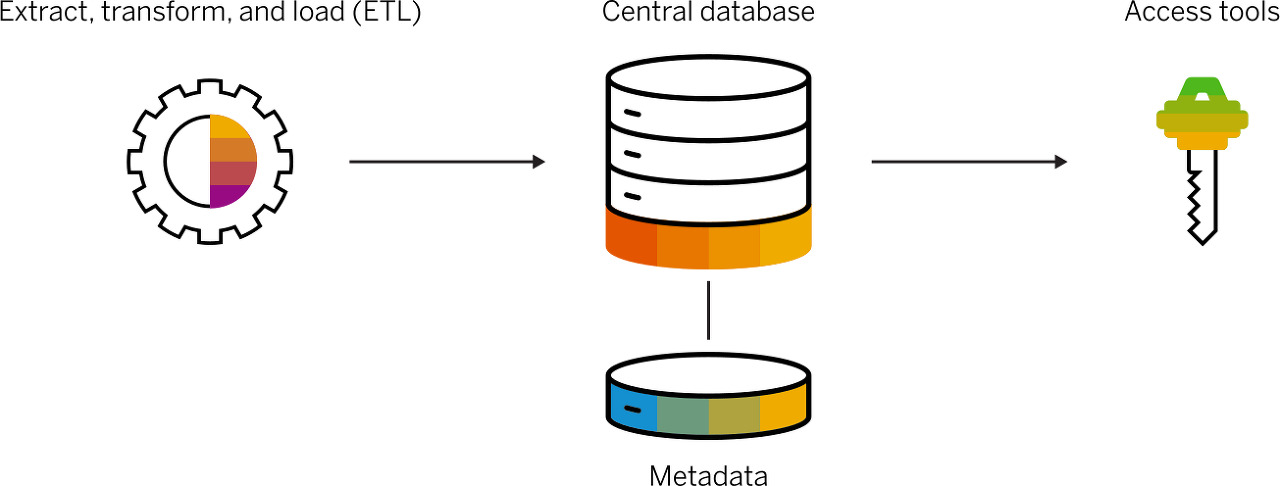
전형적인 가장 기본적인 DW의 주요 구성 요소는 아래와 같다. 여기서 Accss tools는 사용자가 DW의 데이터와 상호작용을 할 수 있도록 지원하는 툴을 이야기한다. 가령 OLAP 툴, 쿼리 툴 등을 말한다. '목적에 맞게 가공' 이 필요하기 때문에 ETL 툴이 존재하는 것을 알 수 있다. 이 외에도 다양한 방식의 아키텍처가 있다. https://www.interviewbit.com/blog/data-warehouse-architecture/ 또는 https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kevinjung423&logNo=221458964153 를 참조하자.
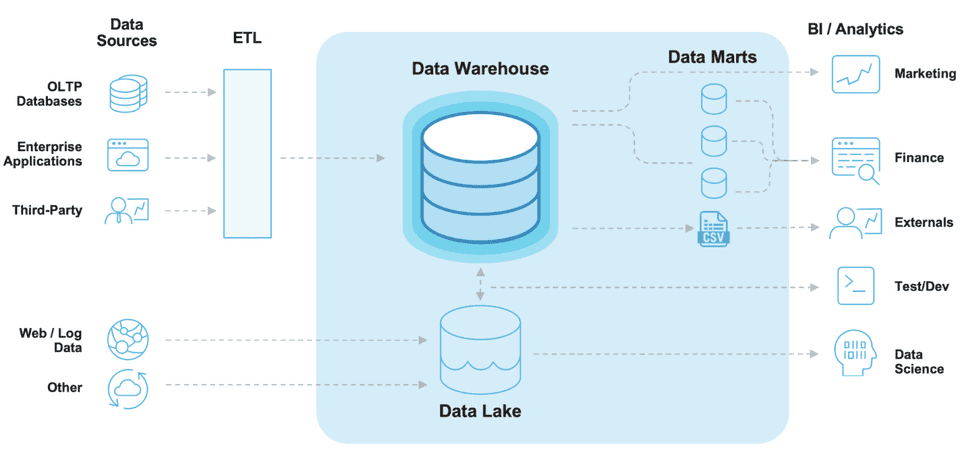
https://www.sap.com/korea/insights/what-is-a-data-warehouse.html 좀 더 자세한 아키텍처를 보자. DW는 Lake나 외부 데이터 소스로 부터 ETL을 거쳐 데이터를 수집한 뒤 Mart에 제공할 수 있다. 개인적인 생각으로는 Data Lake에서도 DW로 넘어갈 떄 ETL이 필요할 것 같다고 생각된다.
https://bomwo.cc/posts/Datawarehouse/ 왜 Datawarehouse를 쓸까? (장점)
- 데이터 레이크보다 안전하다.
- 정보에 기반한 의사결정 가능
- 여러 소스의 데이터 통합(목적에 맞게)
- 데이터 품질, 일과성 확보
DB와 뭐가 다를까?
그럼 이쯤에서 이제 궁금해진다. 그럼 Database와 다른게 뭘까? 포함 관계인걸까? 하고 의문이 생긴다. 구글링을 해보니 DW와 DB를 비교하는 글이 꽤 많았다. 그 중 https://data-newbie.tistory.com/873 이 글을 참고하면 적한한 워크로드부터 차이가 났다 .DW의 경우 분석/보고/빅데이터이며 DB는 트랜잭션 처리 목적으로 적합하다. 또한 DW는 스타 스키마/눈송이 스키마와 같이 비정규화 된 스키마이며 DB는 정적스키마이다. 아무래도 DW는 빅데이터용이기 때문에 I/O를 최소화하고 데이터 처리량을 최대화 하는데에 최적화 되어있다.
*스타 스키마와 눈송이 스키마
둘 다 DW에서 사용되는 다차원 데이터 모델이다. 스카 스키마는 정말 정규화를 사용하지 않고, 스노우 플레이크 스키마는 데이터 중복 제거를 위한 정규화를 사용한다. 저 자세한 내용은 https://sunrise-min.tistory.com/entry/Star-schema%EC%99%80-Snowflake-schema-%EB%B9%84%EA%B5%90 참조하는 것이 좋다.DW의 단점은 무엇일까?
- '목적에 맞는' 이기 때문에 '목적'이 명확하지 않으면 혼란 발생
- 데이터 불일치 문제가 발생할 수 있다.
- DW 구축에 공수가 많이 들어간다.
- 처음에 설계한 것과 후에 목적이 매우 달라지면 가치 창출의 어려움이 생긴다.
DW의 종류
- EDW(Enterprise Data Warehouse): 비즈니스 정보를 전체 조직에서 사용하고 분석할 수 있도록 하는 DB 1개 이상의 모음을 이야기한다. EDW의 장점 중 하나는 데이터 표준화이다. 효율적인 분석을 위해선 데이터의 형식을 동일하게 맞추는 데이터 표준화가 필요한데, DW의 ETL TOOL을 이용하여 이를 수행할 수 있다.
- RDW(Real-Time Data Warehouse): 말 그대로 실시간 데이터를 저장하는 것이다.
- ADW(Analytical Data Warehouse):
- DM(Data Mart): Data Warehouse의 간단한 형태라고 볼 수 있다.
Data Warehouse Concepts: Kimball vs. Inmon Approach
여기 재미난 내용이 있다.https://www.astera.com/type/blog/data-warehouse-concepts/
본부장님이 DW를 설명해주실 떄 위 두 분을 언급하며 한 번 훑어보라고 하셨었다. vs라고 되어있는 거 보니 다른 의견을 가진 두 분인 듯 하다. 두 분이 말하는 것은 데이터 웨어하우스의 설계 방식이며 이 두 분의 방식이 가장 기본적인 방식이라고 한다.

- kimball: ETL Process를 Data mart마다 수행 시키는 것
- inmon: Data mart를 거치지 않고 일단 ETL Process를 수행 한뒤 DW에 저장하고 ETL을 한번 더 거쳐서 mart로 전송하는 것.
아래 그림을 보면 좀 더 이해가 쉬울 것이다.
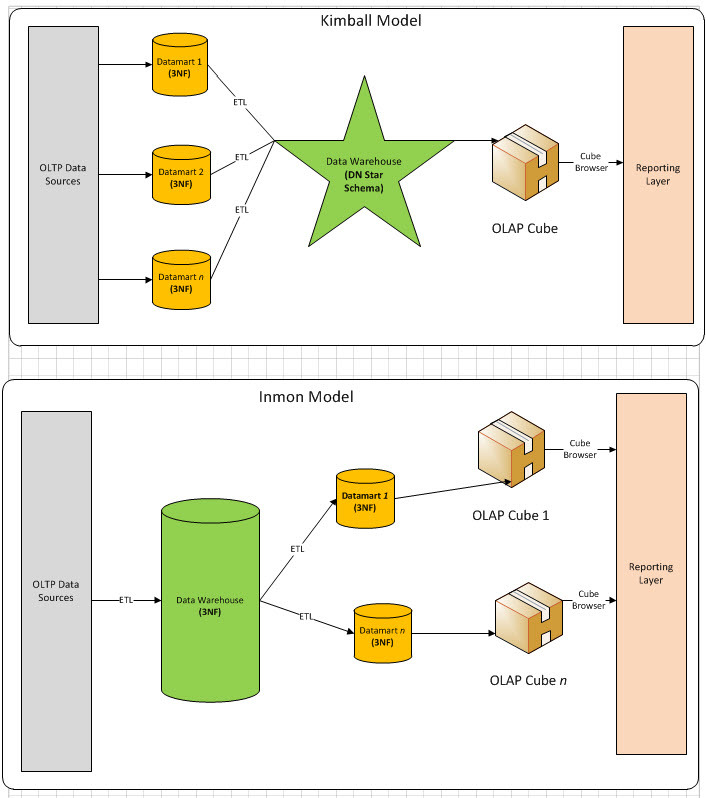
https://bennyaustin.com/2010/05/02/kimball-and-inmon-dw-models/ Data Lakehouse
위 관련 자료들을 서칭하는 중 새로운 것을 발견했다. 바로 Lake와 WareHouse의 장점을 합친 Data Lakehouse라는 것이었다. https://www.databricks.com/kr/glossary/data-lakehouse
위의 아키텍처에서도 살펴봤듯이 Lake와 Mart를 따로 구축하고 연결하여 사용하는 것을 볼 수 있는데 당연하겠지만 이러면 관리에 어려움이 생기고 비용적인 문제도 발생한다. DW와 Lake가 가진 문제점과 이를 각각 관리하는 경우 발생하는 문제점을 해결하고자 등장한 것이 Data Lakehouse 이다.
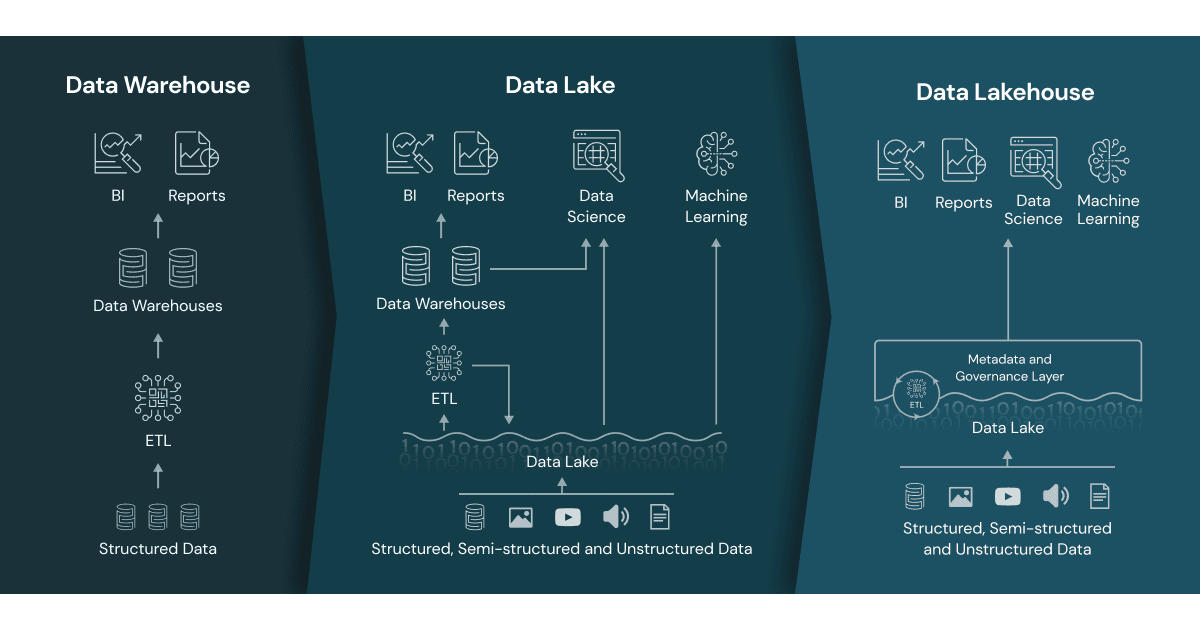
https://www.databricks.com/kr/glossary/data-lakehouse 데이터 레이크하우스는 데이터 레이크 계층 위에 DW 역할의 계층을 통합하는 것이다. DW의 데이터 관리 구조화 기능과 Lake의 저렴하고 유연한 스토리지를 사용하는 것이다. 즉, 저장은 Lakehouse에 저장하되, 여기에서 DW의 ACID 트랜잭션 지원, Star Schema, Snowflake Schema를 지원하는 식이다. 데이터브릭스와 스노우플레이크가 데이터 레이크 하우스 시장의 대표주자라고 한다. 더 자세한 내용은 http://www.itdaily.kr/news/articleView.html?idxno=208876 를 참고해보자.
DATA MART
데이터 마트란 단일 주제 또는 LOB(Line of Business) 초점을 맞춘 단순한 형태의 data warehouse를 의미한다. 데이터 웨어하우스는 전사적 데이터를 다뤘다면 웨어하우스에 비해 좀 더 목적 특화 되어 있으며 유연성과 접근성이 뛰어나다. Data Warehouse 없이 Mart만 구성하는 경우도 있다.
DM과 DW의 차이점은 DW가 훨씬 많은 데이터를 가지고 있으므로 훨씬 더 세분화되고 복잡한 정보를 얻을 수 있다.
* LOB: ERP, CRM, MES 같은 기업용 비즈니스 APPLICATION.
(출처: https://vikira.tistory.com/entry/LOB-Line-Of-Business-%EB%9E%80)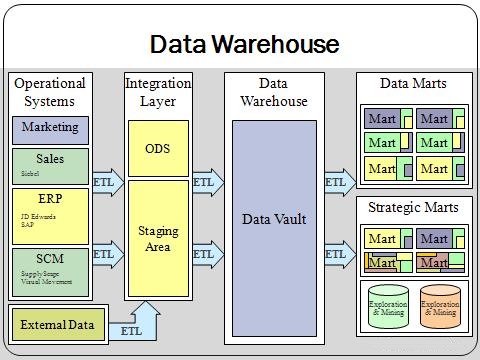
https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0_%EB%A7%88%ED%8A%B8#/media/%ED%8C%8C%EC%9D%BC:Data_warehouse_overview.JPG Data Mart를 왜 쓸까? (장점)
- 필요한 데이터만 존재하므로 데이터 조회 성능이 향상된다.
- Data Mart로 분리하여 각 영역별로 권한 등 각자 관리가 가능하다.
- SSOT(Single Source Of Truth, 단일 진실 공급원)
- - 중앙화된 특성으로 인해 해당 Mart 사용자들이 동일한 데이터 기반의 의사결정이 가능해진다.
- 데이터 기반 예측 신뢰도가 높아진다.
- 모든 구성원들의 요구를 만족하며 구축되어야하는 Warehouse에 비해 단순하며 그로인해 구축 속도 또한 빠르다.
DB와 뭐가 다를까?
그럼 또 궁금해진다 DB와 뭐가 다른가?
https://aws.amazon.com/ko/what-is/data-mart/ 에 의하면 '용도의 차이' 인 것을 알 수 있다. Mart의 경우 정보 검색/분석을 위함이며 DB는 정보 수집/관리 저장을 위함이다. 그래서 DB에서 Tool을 이용해 데이터를 다루어 Mart로 전송시킬 수 있다.
Data Mart의 단점은 무엇일까?
- Mart 간 데이터 불일치
- 너무 많은 양의 Mart는 혼란을 초래함
- 대규모 비즈니스 요구에 적합하지 않음
참고
'2023년' 카테고리의 다른 글
devfest 2023 in songdo (0) 2023.12.10 centOS7 + Superset + Oracle (0) 2023.03.02 Python OCR (5) 2023.03.02 Superset 설치 메모 (0) 2023.02.07 Oracle Study (4) 2023.01.11
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
