
-

CHAPTER1. 지금, 데이터 품질에 주목해야 하는 이유
Data Downtime은 신뢰할 수 없는 데이터가 너무 많을 때 발생한다.
신뢰할 수 있는 데이터를 확보를 위한 여정은 마라톤에 비유할 수 있다.데이터 품질이란?
데이터 품질은 신뢰성, 완전성, 정확성을 측정하는 기능적인 측면부터 구체화되기 시작했다. 또한, 비즈니스 요구 사항 충족여부를 확인하는 강력한 요소이다.
왜 데이터 품질이 2020년대 들어서 더 축구하게 된 것일까?
1. 데이터 다운타임의 증가: 무엇이 데이터 다운 타임을 증가시켰는가?
1-1. 클라우드 마이그레이션
1-2. 다양한 데이터 소스
1-3. 데이터 파이프라인 복잡성 증가
1-4. 데이터 조직 전문성 강화
1-5. 데이터 조직의 분산
2. 데이터 산업 동향
1-1. 데이터 메시: 마이크로서비스 아키텍처의 데이터 플랫폼 버전, 일종의 사회 기술적 시스템 패러다임으로, 사용자가 복잡해지는 아키텍처 및 솔루션과 상호작용할 수 있도록 한다. 기존 모놀리식 데이터 인프라는 단일 중앙 집중형이었던 반면에 메시는 자체 파이프라인 기반의 프로덕트형 데이터 관점에서 분산 도메인별로 데이터 소비자가 활용 할 수 있도록 한다.


처음 Data mesh를 명명한 Zhamak Dehghani는 Data Mesh라는 책을 아예 따로 냈다 1-2. 스트리밍 데이터
1-3. 데이터 레이크 하우스의 등장: 레이크 하우스로 마이그레이션 한다는 것은 데이터 파이프라인이 점점 더 복잡해지고 있음을 시사한다.
😎데이터 메시에 대해 좀 더 알아보자.
" 데이터 메시는 신뢰할 수 있는 고품질 데이터와 범용적인 거버넌스에 의존한 도메인 지향 분산 데이터 아키텍처 " - Zhamak Gehghani
" 데이터 메시는 분산된 소유권을 통해 고급 데이터 보안 문제를 해결하는 아키텍처 프레임워크 " - AWS
" 데이터 메시는 분산 아키텍처 프레임워크를 사용하는 데이터 관리에 대한 접근 방식 " - SAP
" 데이터 메시는 크고 복잡한 조직에서 엔터프라이즈 데이터 플랫폼을 구현하기 위한 아키텍처 패턴 " -MS
" 데이터 메시는, 데이터 관리용 분산형 아키텍처를 기반으로 하는, 데이터를 생각하는 새로운 접근 방식 " -Oracle
'분산'이 키워드인 것 같다. 최초로 명명한 Zhamak Dehghani 또한 '도메인 지향 분산 데이터 아키텍처' 라고 하였다.
데이터 메시의 핵심 아이디어는 데이터를 독립적인 도메인으로 다루는 것이다. 책에서 나온 아키텍처 (https://www.montecarlodata.com/blog-what-is-a-data-mesh-and-how-not-to-mesh-it-up/)또한 도메인 마다 구역을 달리하여 관리하였고, 그로 인해 도메인이 다양한 큰 회사에서 각광받고 있다고 했다.
장점은 도메인별로 데이터를 소유 및 관리하기 때문에, 도메인팀이 책임감을 가지고 주도적으로 빠르게 행동할 수 있어, 데이터 품질이 향상 될 수 있다.
단점은 도메인 팀간의 충돌이 일어 날 수 있고, 도메인 팀별로 운영되어 복잡성(타 도메인의 데이터 접근의 어려움, 통합 분등)과 중복이 일어날 수 있다.
CHAPTER2. 신뢰할 수 있는 데이터 시스템 구축을 위한 블럭 조립
만약 데이터 레이크 속 데이터 변환하고 있고, 그것의 스키마에 대한 어떤 가정을 세웠따면 눈을 감은 채 ETL 프로세스를 처리하는 위험한 짓을 하고 있는 것이다.
운영 데이터와 분석 데이터의 차이
-운영 데이터: 일상적인 운영을 통해 생성된 데이터, OLTP
-분석 데이터: 의사 결정에 활용되는 데이터, OLAP
운영 데이터로 비즈니스를 운영하고 분석 데이터로 비즈니스를 관리한다.
데이터 웨어하우스: 스키마 수준의 테이블 타입
1. 아마존 레드시프트: 최초의 클라우드 DW
2. 구글 빅쿼리
3. 스노우플레이크
데이터 레이크: 파일 수준의 조작
-극초기의 데이터 레이크는 주로 Apache Hadoop Map Reduce와 HDFS를 기반으로 구축되었고, SQL 엔진으로 데이터를 쿼리하기 위해 Hive를 활용했다.
-Apache Spark로 Data Lake 유지 용이성이 극대화 되고, 분산처리가 가능해졌다.
늪지화
시간 흐름에 따라 데이터 레이크가 기술적 부채와 암묵적 지식을 발생시키는 경향
데이터 레이크는 데이터 웨어하우스와 근래 차이가 좁혀지고 있다. 우수한 성능의 SQL, 스키마 도입, ACID, 관리 서비스 등의 기능추가가 이를 가능케 했다.
데이터 다운타임 체크리스트
✅ 최신 상태인가?
✅ 완전한가?
✅ 필드가 예상 범위 내인가?
✅ NULL 비율이 예상보다 높은 것은 아닌가?
✅ 스키마가 변경되었는가?
데이터 품질은 웨어하우스에서 만들어진 변화의 기록인 쿼리로그를 분석하여 얻을 수 있다.
데이터 카탈로그 설계 시 고려해야 할 점
1. 데이터 저장장소
2. 데이터의 중요도
3. 데이터가 나타내는 것
4. 데이터의 관련성과 관련 중요도
5. 데이터의 사용방도
데이터 카탈로그를 구축하는데 첫째는 다운 스트림 이해관계자와 협력해 중요한 데이터 파악 및 문서화 그리고 카탈로그화 해야한다. 이 후 데이터 책임자를 선정한다.
데이터 품질을 우선화하는 카탈로그의 특징
1. 셀프 검색 서비스 및 자동화: 데이터 툴링을 위한 셀프 서비스, 자동화, 워크플로 조정 기능은 데이터 파이프라인 단계 사이의 사일로를 제거한다.
2. 데이터 진화에 따른 확장성: 나쁜 정보나 직감 기반 의사결정이 아닌 지능적이고 데이터에 입각한 의사 결정이 가능해진다.
3. 분산 검색을 위한 데이터 계보: 데이터 검색은 데이터 자산 간 업스트림 및 다운스트림 의존성을 매핑하기 위해 테이블 및 필드 레벨 계보에 크게 의존하고, 계보는 자산 간 연결을 기반해 파이프라인 문제해결을 도와준다.
CHAPTER 3. 데이터 수집, 정제, 변환, 테스트
우리 인생과 마찬가지로 데이터는 결코 완벽하게 신뢰할 수 없다. 이 사실을 빨리 받아들일 수록 좋다.
데이터 수집
1. 애플리케이션 로그 데이터를 수집할 땐 다음을 고려해야 한다.
- 매우 다양한 구조
- 타임스탬프, 대부분의 애플리케이션 로그는 타임스탬프를 포함하고 있다.
- 로그 레벨(INFO,WARN,ERROR 등)
- 목적, 무작위 수집보다는 진단과 감사를 통해 로그를 선별하여 수집해야 한다.
2. API 응답: API는 두 프로그램의 매개체로 특정 형식의 요청과 응답으로 이루어져 있으며 수집할 땐 다음을 고려해야 한다.
- 구조, JSON 또는 XML
- 응답코드, API는 상태코드를 포함한다.
- 목적, 특정 상황에 유용한 정보만을 포함하는지 고려해야 한다.
3. 센서 데이터 데이터를 수집할 땐 다음을 고려해야 한다.
- 노이즈: 센서데이터는 노이즈가 굉장히 많으므로 이를 위한 오류값 제거, 평활화 등의 변환을 수행해야 하므로 항상 안정적이고 일관된 스트림이 필수적이다.
- 고장 모드: 센서는 고장이 났을 때 데이터를 쏘지 못할 수 있다.
- 목적: 목적에 따라 중점을 둬야하는 기술이 다르다.(데이터 처리량, 대기시간 등)
데이터 정제
1. 오류값 제거
2. 데이터셋 특징 평가
3. 정규화
4. 데이터 재구성
5. 시간대 변환
6. 유형(data type) 변환
실시간 처리를 위한 데이터 품질
데이터 품질은 배치 스트리밍 시스템에서 더 높은 경향이 있지만, 데이터를 실시간으로 스트리밍할 때 오류의 중요성은 훨씬 커진다.
아마존 키네시스
아마존 키네시스는 실시간 데이터를 위한 서버리스 스트리밍 도구이다. 온디맨드 가용성, 비용 효율성, 철저한 SDK, AWS 인프라 통합 등의 이점을 가지고 있다. AWS 람다 기능을 통해 관리되며, 람다 함수는 닷넷, 고, 자바, Node.js, python, Ruby로 작성 가능하다.
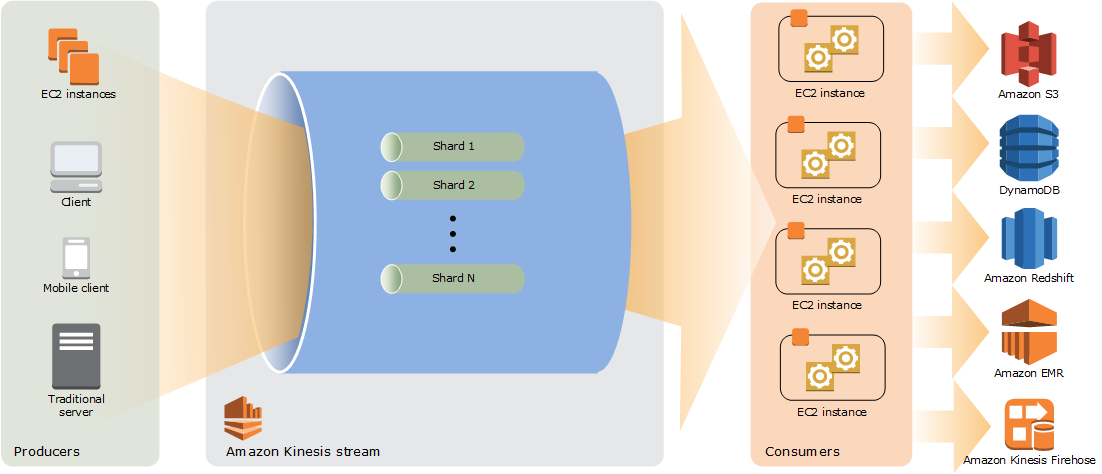
https://docs.aws.amazon.com/ko_kr/streams/latest/dev/key-concepts.html 아파치 카프카
아파치 카프카는 오픈 소스 이벤트 스트리밍 플랫폼이다. 카프카는 내가 몇 번 실습을 진행했었다. (이게 벌써 4년전..?)
2020.10.06 - [2020년/Development] - [Kafka] #1 카프카를 알아보자
2020.10.06 - [2020년/Development] - [Kafka] #2 카프카를 써보자
기본적으로 아파치 카프카 스트림은 JMX(Java MAnagement Extensisons)를 통해 스트리밍 메트릭을 보고한다.
카프카와 키네시스를 비교했을 때, 키네시스는 좀 더 많은 언어를 지원하고, 카프카는 더 높은 처리량을 보이고 데이터 보존기간이 길다. 소규모 조직에는 쉬운 관리형인 키네시스를 대규모 조직에는 카프카를 활용하는 것이 적합하다.
데이터 품질 테스트의 일반적인 체크사항은 다음과 같다.
1. NULL 유무
2. 용량
3. 분포
4. 유니크함
5. 정보 불변속성
dbt 테스트
1. 단일 테스트: 특정 모델을 참조하는 독립 실행형 SQL 테스트
2. 일반 테스트: 여러 모델에서 재사용할 수있는 'templatized' 테스트, 매개변수화된 SQL 쿼리 형식을 취하며 인수를 사용할 수 있다.
dbt에서 확인해야 할 사항들
1. 기술 부채 및 유지: 테스트를 코드형태로 관리한다.
2. 테스트 피로 및 암묵적 지식
3. 제한된 가시성
데이터 품질 관리도구1. 그레이트 익스펙테이션스(Great Expectations):
2. Apache Deequ
3. Apache Airflow
4. SQL 검사 연산
https://docs.greatexpectations.io/docs/home/
Home | Great Expectations
Learn everything you need to know about GX Cloud and GX Open Source Software (OSS)
docs.greatexpectations.io
https://github.com/awslabs/deequ
GitHub - awslabs/deequ: Deequ is a library built on top of Apache Spark for defining "unit tests for data", which measure data q
Deequ is a library built on top of Apache Spark for defining "unit tests for data", which measure data quality in large datasets. - awslabs/deequ
github.com
서킷 브레이크 방법론
데이터가 품질 임곗값들을 충족하지 못할 때, 파이프라인 작동을 중지해 버리는 것
1. 서킷 폐쇄: 데이터가 파이프라인을 통해 흐르고 있다.
2. 서킷 개방: 데이터가 파이프라인을 통해 흐르고 있지 않다.
서킷 브레이커를 사용하기 위해 다음과 같은 세 가지 솔루션이 필요하다(이누이트 전 최고 데이터 설계자 산딥 우탐찬디)
1. 데이터 계보
2. 파이프라인 전반의 데이터 프로파일링
3. 프로파일링을 통해 발견된 문제를 통해 서킷을 자동으로 트리거 하는 기능
REFERENCES
https://www.samsungsds.com/kr/insights/data_mesh_in_financial_services.html
https://brownbears.tistory.com/661
'2024년' 카테고리의 다른 글
20대의 끝, 나의 30대의 시작은 성공적이었을까? #2 도전 (2) 2024.07.03 20대의 끝, 나의 30대의 시작은 성공적이었을까? #1 대회 (2) 2024.07.01 견고한 데이터엔지니어링 #PART 1 (0) 2024.05.29 libnsl.so.1()(64bit) is needed by oracle-instantclient (0) 2024.05.09 프로젝트를 끝내며, 회고 (0) 2024.04.16
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!
