
-
1. NL(Lested Loop) Join
프로그래밍에서 중첩 반복문을 생각하면 쉬움. 아래처럼 outer 에서 시작해서 inner를 처리.
for ... (outer)for ... (inner)예를 들어 아래와 같을 때
a b - driving table
- 선행테이블
- outer table- driven table
- 후행테이블
- inner tableWHERE TableA a, TableB, b-- a: outer, b: inner수행 과정
아래 4단계를 반복.
1. a에서 주어진 조건에 만족하는 첫 번째 행을 스캔(조건으로 필터-이래서 outer table의 역할이 크다는 것)
2. a의 join key를 가지고 b에 join key의 존재 여부 확인하고 join을 시도
3. b의 인덱스에 a의 join key가 존재하는지 확인(역으로 확인), 만약에 존재하지 않으면 a 테이블 데이터가 삭제됨
4. 인덱스에서 추출한 레코드 식별자로 후행 테이블 엑세스
출처: http://www.gurubee.net/lecture/2388 SELECT /*+ USE_NL (B) */a.*,b.*FROM tableA a, tableB, bWHERE 1=1AND a.cd = b.cdAND a.type = 'x'AND a.yn = 'Y'AND b.yn = 'N'* Outer의 결과를 가지고 Inner 를 접근하기 때문에 Outer가 중요함
* Index를 통한 Random Access위주의 Join
장점 단점 1. Inner Table 행의 " 작은" 하위 집합과 Outer Table의 각 행이 일치할 때 성능이 좋음
2. 부분 범위 처리가 가능한 Join 방식으로 OLTP에 적합1. 대규모, 대용량 처리 시 성능 저하
2. Inner Table 행의 "많은" 하위 집합과 Outer Talble의 각 행이 일치할 때 성능 저하
3. Inner Table은 Index가 반드시 존재해야 함2. Sort-Merge Join
- Join column을 기준으로 데이터를 정렬하여 Join을 수행
- Random Access로부터 부담이 되는 넓은 범위의 데이터를 처리할 때 사용
select /*+ USER_MERGE(A B) */from tableA a, tableB bwhere a.joinkey = b.joinkeyand a.type = 1and b.value = 'a';수행 과정
[1-2] 와 [3-4]는 조건에 만족하는 모든 행에 대해 반복적으로 수행함
1. a에서 주어진 조건에 만족하는 행을 찾음
2. a의 join key를 기준으로 정렬 작업 수행
3. b에서 주어진 조건에 만족하는 행을 찾음
4. b의 join key를 기준으로 정렬 작업 수행
5. 정렬 된 결과를 이용하여 조인을 수행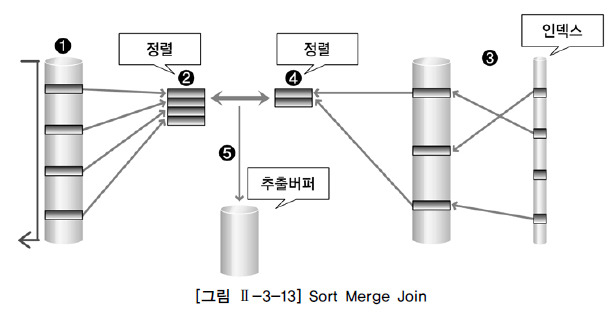
출처: http://www.gurubee.net/lecture/2388 * 정렬할 임시영역이 필요함, 이 영역은 항상 충분한 공간이 할당되어 있어야 함
3. Hash Join
- 말 그대로 해싱 기법을 이용한 조인 기법으로, 조인 컬럼을 기준으로 해시 함수를 사용하여 서로 동일한 해시 값을 갖는 것들 사이에 실제 값이 같은지를 비교하면서 조인 수행
- 정렬 작업의 부담, 인덱스가 없음 등 NL JOIN, SORT MERGE JOIN의 문제점을 해소하기 위한 대안
select /*+ ORDERD USE_HASH(b) */from tableA a, tableB bwhere a.joinkey = b.joinkeyand a.type = 1and b.value = 'a';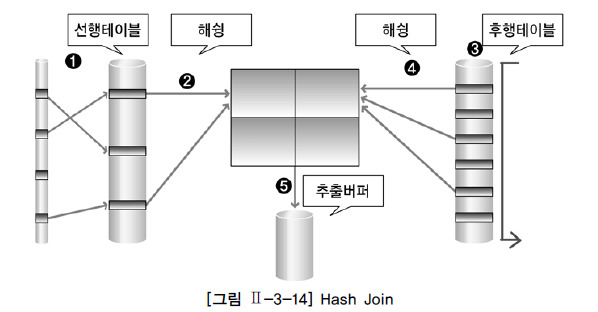
출처: http://www.gurubee.net/lecture/2388 수행과정
아래 4단계 반복
1. 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
2. 선행 테이블의 join key를 기준으로 해시 함수를 적용하고 hash table 생성 * Hash Table에는 Join key 뿐 아니라 SQL에 사용한 모든 컬럼 저장
3. 후행 테이블에서 주어진 조건에 만족하는 행을 찾음
4. 후행 테이블의 join key를 기준으로 해시 함수를 적용하고 해당 버킷을 찾음(2번에서 생성한)* Hash Table은 PGA 영역에 할당 된 Hash Area에 저장함, 이 때문에 해시 조인 시 래치 획득 과정 없이 PGA에서 빠르게 데이터 탐색해서 속도가 좋음
* Sort-Merge도 PGA 영역에 할당하나, 소트 머지는 정렬 후 PGA에 담을 때 크기가 모자라면 Temp Disk에 데이터를 작성하는 과정이 반드시 수행되어 더 느림, Hash는 전혀 일어나지 않음
* 래치(Latch): 다중 프로세스/스레드 환경에서 메모리 자원 동기화를 위한 잠금 기법.
Build와 Probe, 2단계로 이루어짐
1. Build 단계: 해시 테이블 생성
2. Probe 단계: 해시 테이블 탐색
REFERENCES
https://coding-factory.tistory.com/757
위지원데이터 엔지니어로 근무 중에 있으며 데이터와 관련된 일을 모두 좋아합니다!. 특히 ETL 부분에 관심이 가장 크며 데이터를 빛이나게 가공하는 일을 좋아한답니다 ✨
'2024년' 카테고리의 다른 글
[Tableau] 초보사용자의 기록 - 조회, 초기화 버튼 만들기 (3) 2024.09.27 밤새고 정처기 본 후기 🥳 드디어 정처기 끝! (0) 2024.09.12 20대의 끝, 나의 30대의 시작은 성공적이었을까? #3 봉사와 마음건강 (26) 2024.07.16 20대의 끝, 나의 30대의 시작은 성공적이었을까? #2 도전 (2) 2024.07.03 20대의 끝, 나의 30대의 시작은 성공적이었을까? #1 대회 (2) 2024.07.01
데이터를 사랑하고 궁금해하는 기록쟁이입니다! 😉 Super Data Girl이 되는 그날까지🏃♀️ 화이팅!

